Microsoft Concept Graph 是一个大规模的英文 Taxonomy,其中主要包含的是概念间以及实例(等同于上文中的实体)概念间的 IsA 关系,其中并不区分 instanceOf 与 subclassOf 关系。Microsoft Concept Graph 的前身是 Probase,它过自动化地抽取自数十亿网页与搜索引擎查询记录,其中每一个 IsA 关系均附带一个概率值,即该知识库中的每个 IsA 关系不是绝对的,而是存在一个成立的概率值以支持各种应用,如短文本理解、基于 taxonomy 的关键词搜索和万维网表格理解等。目前,Microsoft Concept Graph 拥有约 530 万个概念,1250 万个实例以及 8500 万个 IsA 关系(正确率约为 92.8%)。关于数据集的使用,MicrosoftConcept Graph 目前支持 HTTP API 调用,而数据集的完全下载需要经过非商用的认证后才能完成。
除了上述知识图谱外,中文目前可用的大规模开放知识图谱有 Zhishi.me[101]、Zhishi.schema[102]与XLore[103]等。Zhishi.me 是第一份构建中文链接数据的工作,与 DBpedia 类似,Zhishi.me 首先指定固定的抽取规则对百度百科、互动百科和中文维基百科中的实体信息进行抽取,包括 abstract、infobox、category 等信息;然后对源自不同百科的实体进行对齐,从而完成数据集的链接。目前 Zhishi.me 中拥有约 1000 万个实体与一亿两千万个 RDF 三元组,所有数据可以通过在线 SPARQL Endpoint 查询得到。Zhishi.schema 是一个大规模的中文模式(Schema)知识库,其本质是一个语义网络,其中包含三种概念间的关系,即equal、related与subClassOf关系。Zhishi.schema抽取自社交站点的分类目录(Category Taxonomy)及标签云(Tag Cloud),目前拥有约40万的中文概念与150万RDF三元组,正确率约为84%,并支持数据集的完全下载。XLore 是一个大型的中英文知识图谱,它旨在从各种不同的中英文在线百科中抽取 RDF 三元组,并建立中英文实体间的跨语言链接。目前,XLore 大约有 66 万个概念,5 万个属性,1000 万的实体,所有数据可以通过在线 SPARQL Endpoint 查询得到。
2.2 中文开放知识图谱联盟介绍
中文开放知识图谱联盟(OpenKG)旨在推动中文知识图谱的开放与互联,推动知识图谱技术在中国的普及与应用,为中国人工智能的发展以及创新创业做出贡献。联盟已经搭建有 OpenKG.CN 技术平台,如图 5 所示,目前已有 35 家机构入驻。吸引了国内最著名知识图谱资源的加入,如 Zhishi.me, CN-DBPedia, PKUBase。并已经包含了来自于常识、医疗、金融、城市、出行等 15 个类目的开放知识图谱。
图5 中文开放知识图谱联盟
3 知识图谱在情报分析的案例
3.1 股票投研情报分析
通过知识图谱相关技术从招股书、年报、公司公告、券商研究报告、新闻等半结构化表格和非结构化文本数据中批量自动抽取公司的股东、子公司、供应商、客户、合作伙伴、竞争对手等信息,构建出公司的知识图谱。在某个宏观经济事件或者企业相关事件发生的时候,券商分析师、交易员、基金公司基金经理等投资研究人员可以通过此图谱做更深层次的分析和更好的投资决策,比如在美国限制向中兴通讯出口的消息发布之后,如果我们有中兴通讯的客户供应商、合作伙伴以及竞争对手的关系图谱,就能在中兴通讯停牌的情况下快速地筛选出受影响的国际国内上市公司从而挖掘投资机会或者进行投资组合风险控制(图6)。
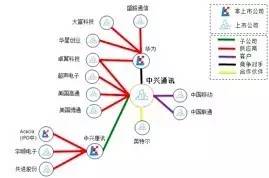
图6 股票投研情报分析
3.2 公安情报分析
通过融合企业和个人银行资金交易明细、通话、出行、住宿、工商、税务等信息构建初步的“资金账户-人-公司”关联知识图谱。同时从案件描述、笔录等非结构化文本中抽取人(受害人、嫌疑人、报案人)、事、物、组织、卡号、时间、地点等信息,链接并补充到原有的知识图谱中形成一个完整的证据链。辅助公安刑侦、经侦、银行进行案件线索侦查和挖掘同伙。比如银行和公安经侦监控资金账户,当有一段时间内有大量资金流动并集中到某个账户的时候很可能是非法集资,系统触发预警(图7)。
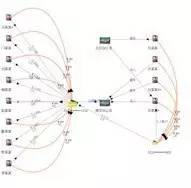
图7 公安情报分析
3.3 反欺诈情报分析
通过融合来自不同数据源的信息构成知识图谱,同时引入领域专家建立业务专家规则。我们通过数据不一致性检测,利用绘制出的知识图谱可以识别潜在的欺诈风险。比如借款人张xx和借款人吴x填写信息为同事,但是两个人填写的公司名却不一样, 以及同一个电话号码属于两个借款人,这些不一致性很可能有欺诈行为 (图8)。
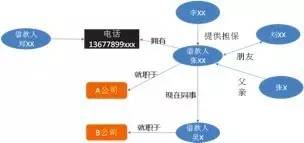
图8 反欺诈情报分析
4 总结
知识图谱是知识工程的一个分支,以知识工程中语义网络作为理论基础,并且结合了机器学习,自然语言处理和知识表示和推理的最新成果,在大数据的推动下受到了业界和学术界的广泛关注。知识图谱对于解决大数据中文本分析和图像理解问题发挥重要作用。目前,知识图谱研究已经取得了很多成果,形成了一些开放的知识图谱。但是,知识图谱的发展还存在以下障碍。首先,虽然大数据时代已经产生了海量的数据,但是数据发布缺乏规范,而且数据质量不高,从这些数据中挖掘高质量的知识需要处理数据噪音问题。其次,垂直领域的知识图谱构建缺乏自然语言处理方面的资源,特别是词典的匮乏使得垂直领域知识图谱构建代价很大。最后,知识图谱构建缺乏开源的工具,目前很多研究工作都不具备实用性,而且很少有工具发布。通用的知识图谱构建平台还很难实现。
转载请注明出处。
 相关文章
相关文章 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
