知识图谱上的类型推理目的是学习知识图谱中的实例和概念之间的属于关系。SDType[76]利用三元组主语或谓语所连接属性的统计分布以预测实例的类型。该方法可以用在任意单数据源的知识图谱,但是无法做到跨数据集的类型推理。Tipalo[77]与LHD[78]均使用 DBpedia 中特有的 abstract 数据,利用特定模式进行实例类型的抽取。此类方法依赖于特定结构的文本数据,无法扩展到其他知识库。
模式归纳(schemainduction)方法
模式归纳方法学习概念之间的关系,主要有基于 ILP 的方法和基于 ARM 的方法。ILP 结合了机器学习和逻辑编程技术,使得人们可以从实例和背景知识中获得逻辑结论。Lehmann 等在[79]中提出用向下精化算子学习描述逻辑的概念定义公理的方法,即从最一般的概念(即顶概念)开始,采用启发式搜索方法使该概念不断特殊化,最终得到概念的定义。为了处理像 DBpedia 这样大规模的语义数据,该方法在[80]中得到进一步的扩展。这些方法都在 DL-Learner[81]中得以实现。Völker 等人在[82]中介绍了从知识图谱中生成概念关系的统计方法,该方法通过 SPARQL 查询来获取信息,用以构建事务表。然后使用 ARM 技术从事务表中挖掘出一些相关联的概念关系。在他们的后续工作中,使用负关联规则挖掘技术学习不交概念关系[83],并在文献[84]中给出了丰富的试验结果。
2 开放知识图谱
本节首先介绍当前世界范围内知名的高质量大规模开放知识图谱,包括 DBpedia[85][86]、Yago[87][88]、Wikidata[89]、BabelNet[90][91]、ConceptNet[92][93]以及Microsoft Concept Graph[94][95]等。然后介绍中文开放知识图谱平台 OpenKG。
2.1 开放知识图谱
DBpedia 是一个大规模的多语言百科知识图谱,可视为是维基百科的结构化版本。DBpedia 使用固定的模式对维基百科中的实体信息进行抽取,包括 abstract、infobox、category 和 page link 等信息。图 2 示例了如何将维基百科中的实体“Busan”的 infobox 信息转换成 RDF 三元组。DBpedia 目前拥有 127 种语言的超过两千八百万个实体与数亿个 RDF 三元组,并且作为链接数据的核心,与许多其他数据集均存在实体映射关系。而根据抽样评测[96],DBpedia 中 RDF 三元组的正确率达 88%。DBpedia 支持数据集的完全下载。
Yago 是一个整合了维基百科与 WordNet[97]的大规模本体,它首先制定一些固定的规则对维基百科中每个实体的 infobox 进行抽取,然后利用维基百科的category进行实体类别推断(Type Inference)获得了大量的实体与概念之间的 IsA 关系(如:“Elvis Presley” IsA “American Rock Singers”),最后将维基百科的 category 与 WordNet 中的 Synset(一个 Synset 表示一个概念)进行映射,从而利用了 WordNet 严格定义的 Taxonomy 完成大规模本体的构建。随着时间的推移,Yago 的开发人员为该本体中的 RDF 三元组增加了时间与空间信息,从而完成了 Yago2[98]的构建,又利用相同的方法对不同语言维基百科的进行抽取,完成了 Yago3[99]的构建。目前,Yago 拥有 10 种语言约 459 万个实体,2400 万个 Facts,Yago 中 Facts的正确率约为 95%。Yago 支持数据集的完全下载。

图2
Wikidata 是一个可以自由协作编辑的多语言百科知识库,它由维基媒体基金会发起,期望将维基百科、维基文库、维基导游等项目中结构化知识进行抽取、存储、关联。Wikidata 中的每个实体存在多个不同语言的标签,别名,描述,以及声明(statement),比如 Wikidata 会给出实体“London”的中文标签“伦敦”,中文描述“英国首都”以及图 3 给出了一个关于“London”的声明的具体例子。“London”的一个声明由一个 claim 与一个 reference 组成,claim 包括property:“Population”、value:“8173900”以及一些 qualifiers(备注说明)组成,而 reference 则表示一个 claim 的出处,可以为空值。目前 Wikidata 目前支持超过 350 种语言,拥有近 2500 万个实体及超过 7000 万的声明[100],并且目前 Freebase 正在往 Wikidata 上进行迁移以进一步支持 Google 的语义搜索。Wikidata 支持数据集的完全下载。
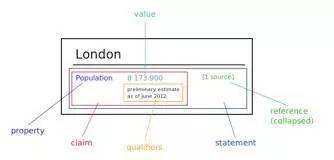
图3
BabelNet 是目前世界范围内最大的多语言百科同义词典,它本身可被视为一个由概念、实体、关系构成的语义网络(Semantic Network)。BabelNet 目前有超过 1400 万个词目,每个词目对应一个 synset。每个 synset 包含所有表达相同含义的不同语言的同义词。比如:“中国”、“中华人民共和国”、“China”以及“people’srepublic of China”均存在于一个 synset 中。BabelNet 由 WordNet 中的英文 synsets 与维基百科页面进行映射,再利用维基百科中的跨语言页面链接以及翻译系统,从而得到 BabelNet 的初始版本。目前 BabelNet 又整合了 Wikidata、GeoNames、OmegaWiki 等多种资源,共拥有 271 个语言版本。由于 BabelNet 中的错误来源主要在于维基百科与 WordNet 之间的映射,而映射目前的正确率大约在 91%。关于数据集的使用,BabelNet 目前支持 HTTP API 调用,而数据集的完全下载需要经过非商用的认证后才能完成。
ConceptNet 是一个大规模的多语言常识知识库,其本质为一个以自然语言的方式描述人类常识的大型语义网络。ConceptNet 起源于一个众包项目 Open Mind Common Sense,自 1999 年开始通过文本抽取、众包、融合现有知识库中的常识知识以及设计一些游戏从而不断获取常识知识。ConceptNet 中共拥有 36 种固定的关系,如 IsA、UsedFor、CapableOf 等,图 4 给出了一个具体的例子,从中可以更加清晰地了解 ConceptNet 的结构。ConceptNet 目前拥有 304 个语言的版本,共有超过 390 万个概念,2800 万个声明(statements,即语义网络中边的数量),正确率约为 81%。另外,ConceptNet 目前支持数据集的完全下载。
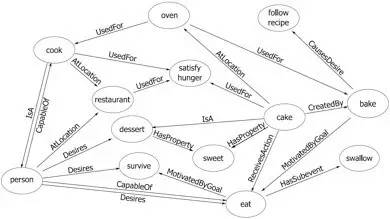
转载请注明出处。
 相关文章
相关文章 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
