本文首先简要回顾知识图谱的历史,探讨知识图谱研究的意义。其次,介绍知识图谱构建的关键技术,包括实体关系识别技术、知识融合技术、实体链接技术和知识推理技术等。然后,给出现有开放的知识图谱数据集的介绍。最后,给出知识图谱在情报分析中的应用案例。
― 漆桂林、高桓、吴天星
东南大学计算机科学与工程学院
本文节选自《情报工程》2017 年第 1 期,知识图谱专题稿件。
1 知识图谱构建技术
本节首先给出知识图谱的技术地图,然后介绍知识图谱构建的关键技术,包括关系抽取技术、知识融合技术、实体链接技术和知识推理技术。
1.1 知识图谱技术地图
构建知识图谱的主要目的是获取大量的、让计算机可读的知识。在互联网飞速发展的今天,知识大量存在于非结构化的文本数据、大量半结构化的表格和网页以及生产系统的结构化数据中。为了阐述如何构建知识图谱,本文给出了构建知识图谱的技术地图,该技术地图如图1所示。整个技术图主要分为三个部分,第一个部分是知识获取,主要阐述如何从非结构化、半结构化、以及结构化数据中获取知识。第二部是数据融合,主要阐述如何将不同数据源获取的知识进行融合构建数据之间的关联。第三部分是知识计算及应用,这一部分关注的是基于知识图谱计算功能以及基于知识图谱的应用。
1.1.1 知识获取
在处理非结构化数据方面,首先要对用户的非结构化数据提取正文。目前的互联网数据存在着大量的广告,正文提取技术希望有效的过滤广告而只保留用户关注的文本内容。当得到正文文本后,需要通过自然语言技术识别文章中的实体,实体识别通常有两种方法,一种是用户本身有一个知识库则可以使用实体链接将文章中可能的候选实体链接到用户的知识库上。另一种是当用户没有知识库则需要使用命名实体识别技术识别文章中的实体。若文章中存在实体的别名或者简称还需要构建实体间的同义词表,这样可以使不同实体具有相同的描述。在识别实体的过程中可能会用到分词、词性标注,以及深度学习模型中需要用到分布式表达如词向量。同时为了得到不同粒度的知识还可能需要提取文中的关键词,获取文章的潜在主题等。当用户获得实体后,则需要关注实体间的关系,我们称为实体关系识别,有些实体关系识别的方法会利用句法结构来帮助确定两个实体间的关系,因此在有些算法中会利用依存分析或者语义解析。如果用户不仅仅想获取实体间的关系,还想获取一个事件的详细内容,那么则需要确定事件的触发词并获取事件相应描述的句子,同时识别事件描述句子中实体对应事件的角色。
在处理半结构化数据方面,主要的工作是通过包装器学习半结构化数据的抽取规则。由于半结构化数据具有大量的重复性的结构,因此对数据进行少量的标注,可以让机器学出一定的规则进而在整个站点下使用规则对同类型或者符合某种关系的数据进行抽取。最后当用户的数据存储在生产系统的数据库中时,需要通过 ETL 工具对用户生产系统下的数据进行重新组织、清洗、检测最后得到符合用户使用目的数据。
1.1.2 知识融合
当知识从各个数据源下获取时需要提供统一的术语将各个数据源获取的知识融合成一个庞大的知识库。提供统一术语的结构或者数据被称为本体,本体不仅提供了统一的术语字典,还构建了各个术语间的关系以及限制。本体可以让用户非常方便和灵活的根据自己的业务建立或者修改数据模型。通过数据映射技术建立本体中术语和不同数据源抽取知识中词汇的映射关系,进而将不同数据源的数据融合在一起。同时不同源的实体可能会指向现实世界的同一个客体,这时需要使用实体匹配将不同数据源相同客体的数据进行融合。不同本体间也会存在某些术语描述同一类数据,那么对这些本体间则需要本体融合技术把不同的本体融合。最后融合而成的知识库需要一个存储、管理的解决方案。知识存储和管理的解决方案会根据用户查询场景的不同采用不同的存储架构如 NoSQL 或者关系数据库。同时大规模的知识库也符合大数据的特征,因此需要传统的大数据平台如 Spark 或者 Hadoop 提供高性能计算能力,支持快速运算。
1.1.2 知识计算及应用
知识计算主要是根据图谱提供的信息得到更多隐含的知识,如通过本体或者规则推理技术可以获取数据中存在的隐含知识;而链接预测则可预测实体间隐含的关系;同时使用社会计算的不同算法在知识网络上计算获取知识图谱上存在的社区,提供知识间关联的路径;通过不一致检测技术发现数据中的噪声和缺陷。通过知识计算知识图谱可以产生大量的智能应用如可以提供精确的用户画像为精准营销系统提供潜在的客户;提供领域知识给专家系统提供决策数据,给律师、医生、公司 CEO 等提供辅助决策的意见;提供更智能的检索方式,使用户可以通过自然语言进行搜索;当然知识图谱也是问答必不可少的重要组建。
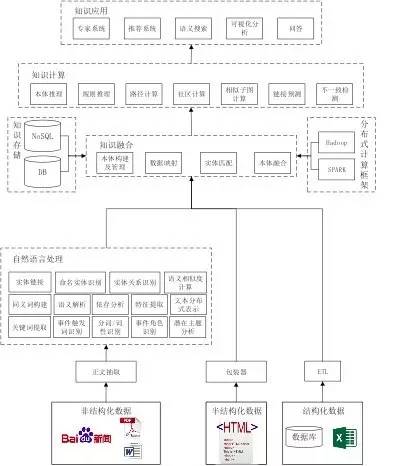
图1
从上图可以看出,知识图谱涉及到的技术非常多,每一项技术都需要专门去研究,而且已经有很多研究成果。由于篇幅的限制,本文重点介绍知识图谱构建和知识计算的几个核心技术。
1.2 实体关系识别技术
最初实体关系识别任务在 1998 年 MUC(Message Understanding Conference)中以 MUC-7 任务被引入,目的是通过填充关系模板槽的方式抽去文本中特定的关系。1998 后,在 ACE(Automatic Content Extraction)中被定义为关系检测和识别的任务;2009 年 ACE 并入 TAC (Text Analysis Conference),关系抽取被并入到 KBP(knowledgeBase Population)领域的槽填充任务。从关系任务定义上,分为限定领域(Close Domain)和开放领域(Open IE);从方法上看,实体关系识别了从流水线识别方法逐渐过渡到端到端的识别方法。
基于统计学的方法将从文本中识别实体间关系的问题转化为分类问题。基于统计学的方法在实体关系识别时需要加入实体关系上下文信息确定实体间的关系,然而基于监督的方法依赖大量的标注数据,因此半监督或者无监督的方法受到了更多关注。
转载请注明出处。
 相关文章
相关文章 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
