第二个改进就是我们做经历回放的方式。旧方法做经历回放的时候会给所有的经历附一个相同的权重。然而相等的权重并不是一个好的思想,如果给所有的经历给一个优先级,你可能做得更好一些。我们仅仅采用了以此误差的绝对值,它表示在一个时刻的某一个特定状态有多么好或者多么差。那些你并没有很好的理解的经历才是所有的经历中你最想回放的。因为需要更多的更新来矫正你的键值。
决斗网络(DuelingNetwork)
第三个改进就是把Q 网络分成两个信道。一部分用来计算当你忽略了一些动作的时候你会得到多少奖励(幻灯片中的action-independent),另一部分用来计算实际中当你采取了某一个特定的动作之后你会做得多么好。然后将两个网络的计算结果求和。然后取两者的总和。正如前面视频中演示的,如果你把这个结果正则化,结果会发现这两个通道会闪烁,因为它们有不同的扩展(scaling)属性。将两个网络分开,去帮助神经网络学习更多的东西,这实际上是很有帮助的。
它们通过在Google 利用下面的结构(Gorila)来让系统加速,这很适合海量数据。
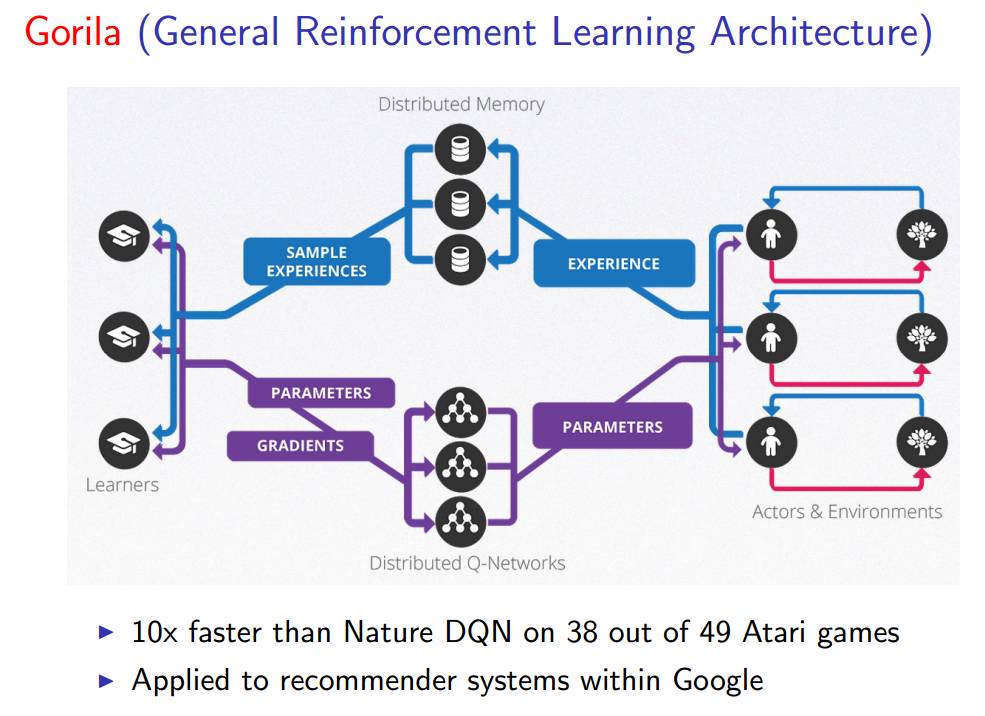
Gorila 结构运行在很多不同的机器上,这让它们可以共同运行深度 Q 网络。我们有许多个代理并行运行的实例,有我们环境的许多不同的实例,这些环境都是基于许多不同的机器,这样便能让我们在力所能及的情况下生成尽可能多的经历。
这些经历被存放在一个分布式的经历回放记忆(experience replay memory)中。本质上就是将所有并行的代理的经历收集起来并且以分布式的方式存储。我们由很多学习器能够在这些经历中并行采样。一旦你有了这个经历回放的缓存,我们可以从中读取很多不同的东西并且将其应用于系统的更新上。然后,从那些学习器返回的参数更新将被共享到我们存储的分布式神经网络中,然后在实际上运行在这些机器上的每个代理共享。
那么,在没有Google 的资源的情况下,我们如何做才能加速强化学习呢?可以使用异步强化学习:
利用标准 CPU 的多线程
将一个代理的多个实例并行执行
线程间共享网络参数
并行地消除数据地相关性
经历回放的可替代品
在单个机器上进行类似于 Gorila 的加速!
基于策略的深度强化学习
深度策略网络

策略梯度

Actor-Critic算法

异步优势Actor Critic 算法(A3C)

Labyrinth中的异步优势Actor Critic 算法(A3C)
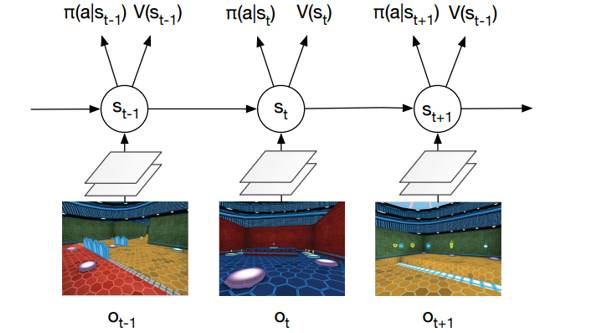
从输入的像素中进行 softmax 策略 π(a|st) 的端到端学习。对环境的观测量 ot 是当前帧的原始像素。状态 st= f(o1, …, ot) 是一个循环神经网络(LSTM)。网络在策略π(a|s) 下同时输出价值 V(s) 和激活函数 softmax 的结果值。任务是收集苹果(+1 分奖励)和逃跑(+10 分奖励)。
深度强化学习中采用异步方法的演示:Labyrinth,如下
我们如何处理高维连续动作空间?

与深度 Q 网络类似,我们在这里有 DPG 算法。希望你现在对深度 Q 网络有了较好的理解,这将有助于你理解下一部分内容。
确定策略梯度(DPG/DeterministicPolicy Gradient)算法
下面是 DavidSilver 关于 DPG 的论文的链接:
深度确定策略梯度

模拟物理中的确定策略梯度算法:
在 MuJoCo 上模拟物理域
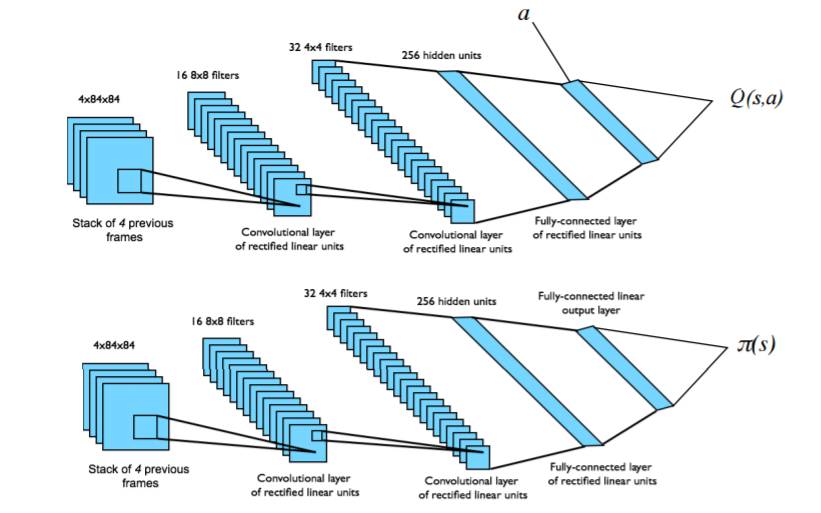
从原始输入的状态 s 中进行控制策略的端对端学习
输入状态 s 是最近 4 个帧 (4 个状态) 的原始数据
对价值 Q 和策略π使用两个分离的卷积神经网络
策略π被朝着能够最大程度提成价值 Q 的方向调节
图为两个分离的卷积神经网络,分别对应 Q 价值函 Q(s,a)和策略π(s)。
然后我们来看一看其他的经典游戏,例如扑克。我们能够使用深度强化学习的方法在多代理的游戏中找到纳什均衡吗?纳什均衡就像多代理决策问题中的解决方案。在这个均衡下,每个代理都满足它们的策略,没人愿意偏离当前的策略。
因此,如果我们找到了纳什均衡,我们就解决了这个小问题。很多研究都在关注如何在更加庞大、有趣的博弈游戏中实现这种均衡。
这里的思想是,我们首先学习一个价值 Q 网络,然后学习一个策略网络,然后挑选一些最佳相应和平均最佳相应之间的动作。
代理在游戏中进行虚拟自我对抗 (FSP)。

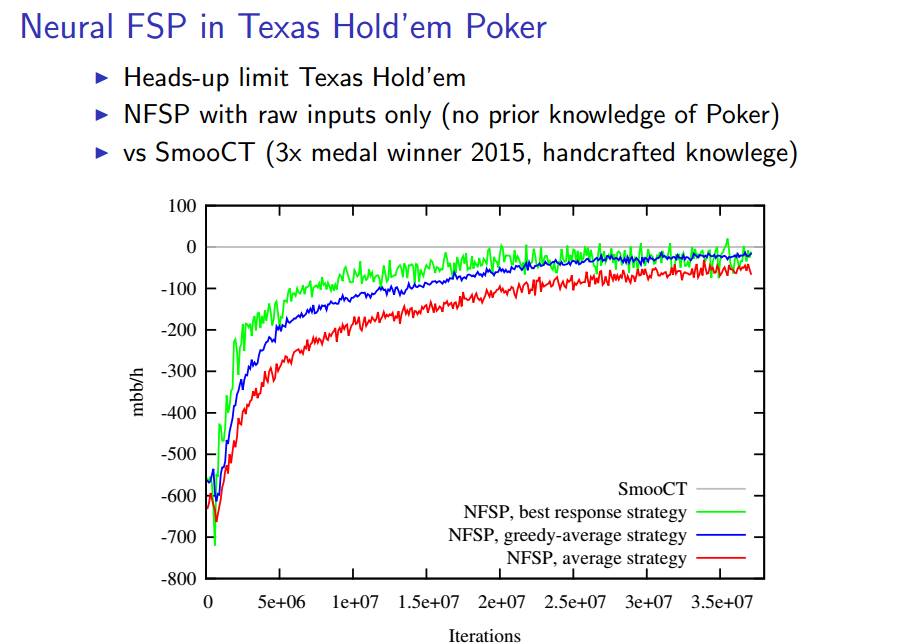
下面的幻灯片阐述了在德州扑克进行 FSP 的结果:随着迭代次数的增加,不同的算法都收敛了。
基于模型的深度强化学习
学习环境的模型
Demo:Atari 的生成模型
复杂的误差使规划富有挑战
传递模型中的误差会在轨迹上复合
规划的轨迹会与执行的轨迹有所不同
在长时间的不正常轨迹结束时,奖励是完全错误的
转载请注明出处。
 相关文章
相关文章 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
