「本质上,这些都是闭环系统,因为学习系统的行为会影响它之后的输入。此外,(1) 学习系统没有像很多其它形式的机器学习方法一样被告知应该做出什么行为;(2) 相反,必须在尝试了之后才能发现哪些行为会导致奖励的最大化;(3) 在大多数有趣并且有挑战性的例子中,当前的行为可能不仅仅会影响即时奖励,还会影响下一步的奖励以及后续的所有奖励。这三个特征是强化学习中最重要的三个区分特征,作为闭环系统的本质、没有关于该采取什么行动和后续的包括奖励信号和完成学习的时间的直接指示。」[2]
强化学习和标准监督学习的区别就在于从来不呈现正确的输入/输出对,也不存在次优化的行为被显式地修正。此外,还关注在线性能。在线性能涉及在对未知领域的探索和当前领域知识的利用之间寻求一个平衡。[4]
我们曾经介绍过强化学习:
并且还有一个视频演示:
前面说了一下什么是强化学习的问题,那么,我们为什么要关注强化学习呢? 简而言之,强化学习是一个通用的决策框架。实际上我们关心的是开发一个能够在现实世界中做出决策的代理(agent)。我们不仅想给它算法并让它采取行动。我们还想让代理做决策。而强化学习可以让代理学会做决策。
强化学习用于具有行动能力的代理
每一个动作(action)都能影响代理将来的状态(state)
通过一个标量的奖励(reward)信号来衡量成功
目标:选择一系列行动来最大化未来的奖励
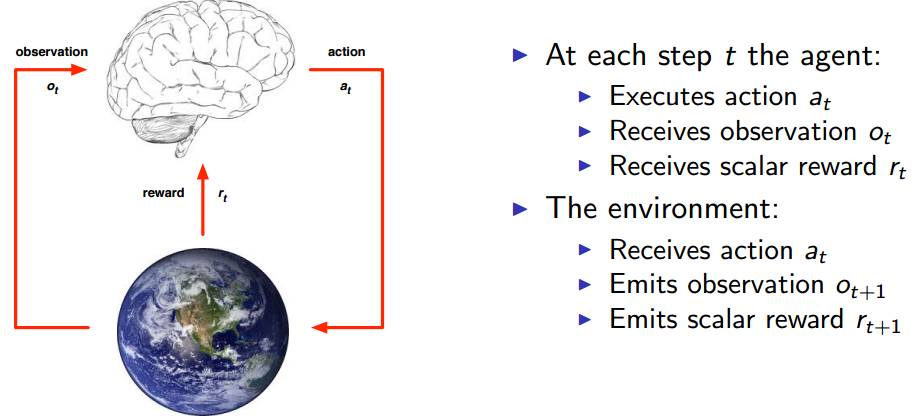
在每一个时刻 t,代理会执行一个动作 at, 收到一个观测信号 Ot, 收到一个标量奖励 rt。外界环境会收到一个动作 at, 发出一个观测信号 Ot+1,发出一个奖励信号 rt+1。
由于每个问题都有其各自不同的特点,所以,为了实现「通用」的目标,我们需要找到它们的共同点和一些规律性的东西。希望大家可以在没有解释的情况下理解上图的内容。图中的大脑是我们所说的代理,图中的地球是代理所处的环境。任何时刻,当代理执行一个动作 at 之后,它将会收到对环境的观测量 Ot 以及来自环境的奖励 rt,同时,收到动作 at 之后,环境会发出下一个观测量 Ot+1,以及奖励 rt+1。这就引入了一个新的概念:状态。

如上图所示,状态是所有经历(experience)的总和,经历就是上图中的第一个序列函数。某时刻 t 的状态 st 是该时刻以及之前所有时刻的所有观测量、奖励以及动作序列的函数。但是,当代理所处的环境具有一种我们所说的完全可观测性之后,就有了上图中的第二个状态函数――某时刻的状态仅仅是该时刻的观测值 Ot 的函数,这样一来,整个经历似乎具备了某种类似于马尔可夫性的性质。
然后,就有了三个新的想法:策略(policy)、价值函数(value function)和模型(model)。

一个强化学习系统的主要组成

一个强化学习的代理可能包含一个或多个下述的组成:
策略:代理的行为函数
价值函数 (Value function):评价一个状态或者行为的好坏及其程度
模型(Model):代理对环境的表征

策略指的是代理的行为,它是从状态到行为的映射。包括确定策略和随机策略。
确定策略:a =π(s)
随机策略:π(a|s)= P[a|s]
价值函数

价值函数是对未来奖励的预测,表示在状态 s 下,执行动作 a 会得到多少奖励?
Q 价值函数表示奖励总值的期望。表示在给定一个策略π,贴现因子γ,和状态 s 下,执行动作 a,获得奖励的综合的期望是多少?
Q 价值函数还能够分解为上图描述的贝尔曼方程。
贝尔曼方程,以其提出者 Richard Bellman 命名,也被称作动态规划方程。它是与动态规划有关的数学优化相关的优化问题的必要条件 [5]。

优化价值函数就是使得价值函数达到可实现的最大值。以此为条件就会得到整个问题的最优解,以及相应的最优策略π*。
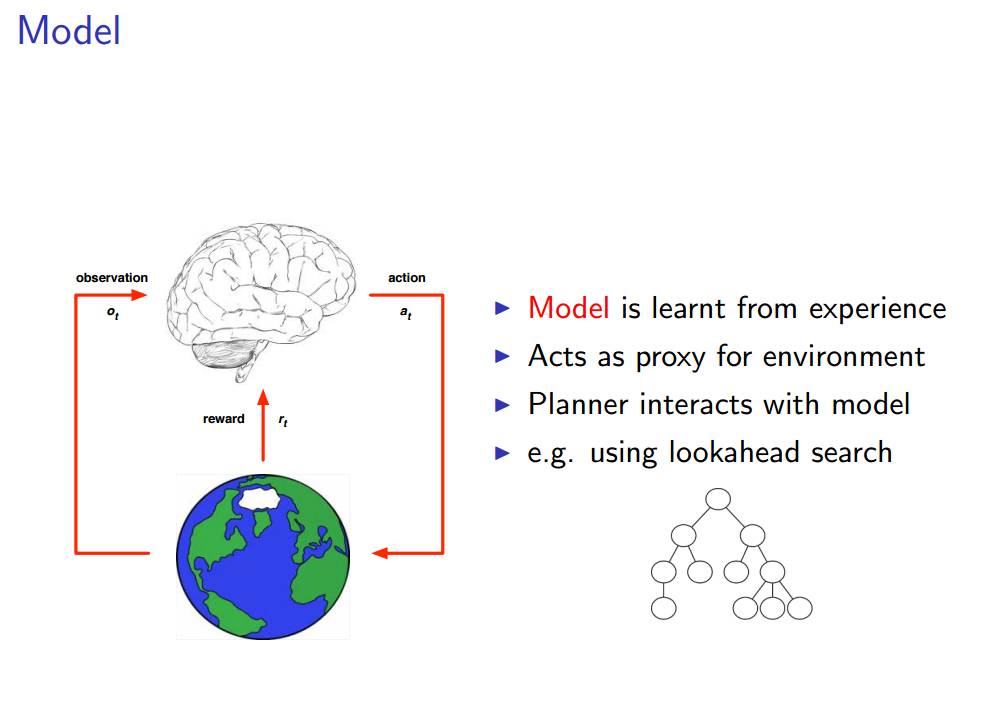
模型:
整个模型就是从经历中学习的过程。
由于我们已经定义了强化学习代理的三个组成部分,所以不难理解,优化其中的任何一个都会得到一个较好的结果。

有三种实现强化学习的途径,分别基于不同的原则。即:基于价值的强化学习,基于策略的强化学习,以及基于模型的强化学习。
基于价值的强化学习,需要估计 Q 价值函数的最大值 Q*,这是在任意策略下能够得到的最大 Q 价值函数。
基于策略的强化学习,直接搜索最佳的策略π*,这将得到能够最大化未来奖励的策略π*。
基于模型的强化学习,构建一个环境的模型,用模型进行诸如前向搜索的规划。
深度强化学习(DeepReinforcement Learning)
什么是深度强化学习?简言之,就是强化学习+深度学习。
转载请注明出处。
 相关文章
相关文章 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
