将强化学习和深度学习结合在一起,我们寻求一个能够解决任何人类级别任务的代理。强化学习定义了优化的目标,深度学习给出了运行机制――表征问题的方式以及解决问题的方式。强化学习+深度学习就得到了能够解决很多复杂问题的一种能力――通用智能。
DeepMind 中深度强化学习的例子有:
游戏:Atari 游戏、扑克、围棋
探索世界:3D 世界、迷宫
控制物理系统:操作、步行、游泳
与用户互动:推荐、优化、个性化
那么,我们如何结合强化学习和深度学习呢?
用深度神经网络来代表
价值函数
策略
模型
用随机梯度下降来优化损失函数
下面的三部分,我们分别讨论三种结合强化学习和深度学习的方法。
基于价值的深度强化学习
基于价值的深度强化学习的基本思想就是建立一个价值函数的表示,我们称之为 Q 函数。
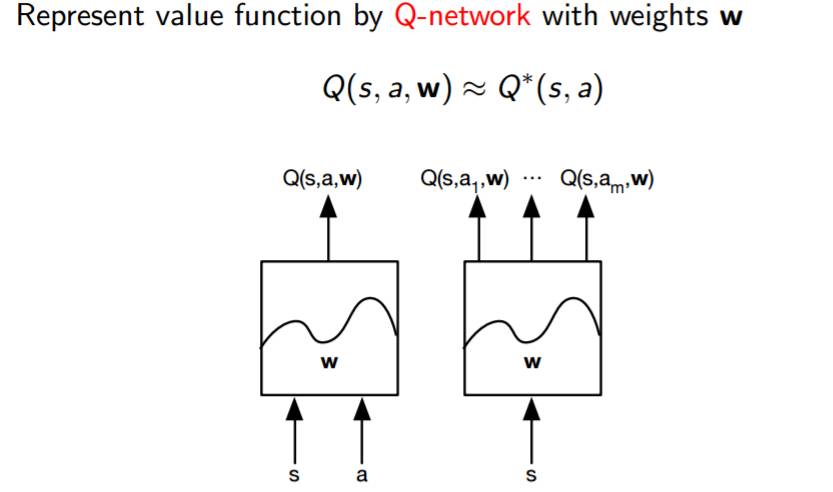
其中:
s =状态
a =动作
w =权值
正如我们在上边图片中看到的一样,基本上就是一个黑盒子,将状态和动作作为输入,并输出 Q 和一些权值参数。
我们会用到基于 Q学习的基本方法。这种方法会想出我们需要的损失函数,而且是以贝尔曼方程作为开始的。

如上图所示,我们等号右边作为优化的目标。现在逐步解释这个算法:将左侧的内容移到等号右边。
随后我们用随机梯度下降的方法去最小化最小均方差 (MSE),一般这个方法在优化的过程中都会奏效的。如果每一个状态和动作都有一个单独的值,那么在这个方法下,价值函数会收敛到一个最优值。不幸的是,由于我们使用的是神经网络,会有两个问题出现:
采样之间的相关性:加入我是一个四处走动的机器人,通过实际数据来学习。我将算法中的每一步视为采取行动的状态,如此一来,这些状态和动作就会和上一次执行的动作非常接近。也就是说,我们采取的方法中存在很强的相关性。
我们从中学习到的目标依赖于目标本身,因此这些都是非平稳的动态。正是由于非平稳动态的存在,我们的近似函数会螺旋式失控,并且导致我们的算法崩溃。
如果我们继续使用神经网络,上述两个问题是不会被解决的。
为了实现稳定的深度强化学习,我们引入的第一个方法是被称为 DQN 的深度强化网络。如下面的 PPT 所描述的,这在 Q 学习的基础上引入了根本的提升。其中的思想非常简单:通过让代理从自己的经历中构建数据集,消除非平稳动态中的所有相关性。然后从数据集中抽取一些经历并进行更新。
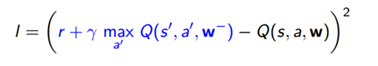

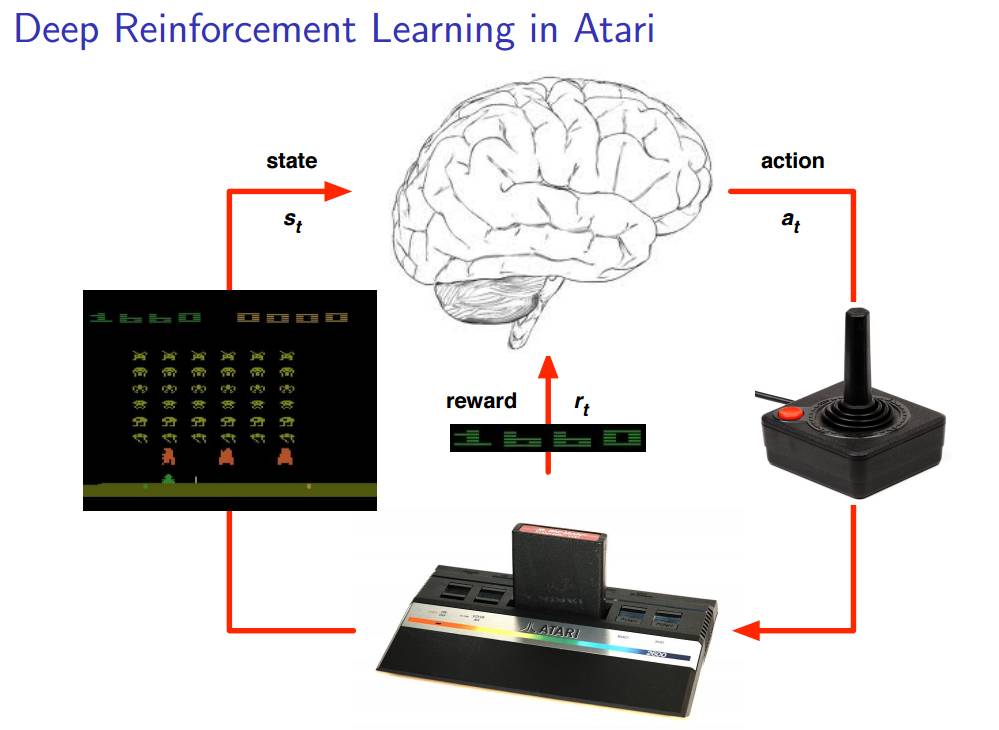
在解释完前面的东西之后,David Silver 给大家举了一个他们 DeepMind 团队的一个例子:Atari 游戏。他们训练出了一个能够将 Atari 游戏玩的很好的系统。相信下面的插图能够有助于读者理解代理和环境(包括状态、动作以及奖励)之间的关系
Atari 中的 DQN
从状态 s 中端对端地学习 Q 价值函数Q(s,a)。
输入状态 s 是最近 4 帧的原始像素组成的堆栈
输出的 Q 价值函数 Q(s,a) 用于 18个操纵杆/按钮的位置
奖励就是每一步动作所对应的得分的变化
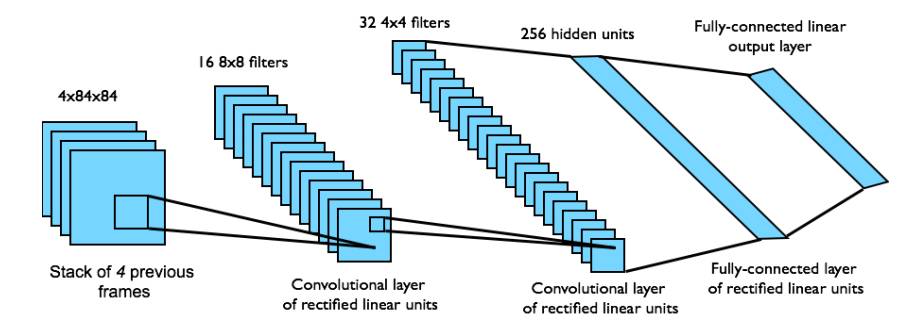
这是一个卷积神经网络 (CNN)
网络结构和超参数在所有的游戏中都是固定不变的。
采用深度 Q 网络的 Atari 的 Demo:
Nature 上关于深度 Q 网络 (DQN) 论文:
GoogleDeep Mind 团队深度 Q 网络 (DQN) 源码:
我们之前也介绍过一次深度 Q 网络 (DQN) :
继 Nature 上发表深度 Q 网络之后,有好多关于 DQN 的改进。但 David 主要关注以下三点:

双深度 Q 网络(Double DQN):
要理解第一个改进,我们首先必须明白 Q 学习中存在的一个问题。问题就踹 MAX 算子上。事实上那样得到的近似值不足以做出决定,并且这个偏差可能在实际应用中导致一系列问题。因此,为了解决这个问题,我们用了两个深度 Q 网络把评价动作的方式分解为两个路径。一个深度 Q 网络用来选择动作,另一个用来评价动作,这在实践中确实很有帮助。
确定优先级的经历回放:
转载请注明出处。
 相关文章
相关文章 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
