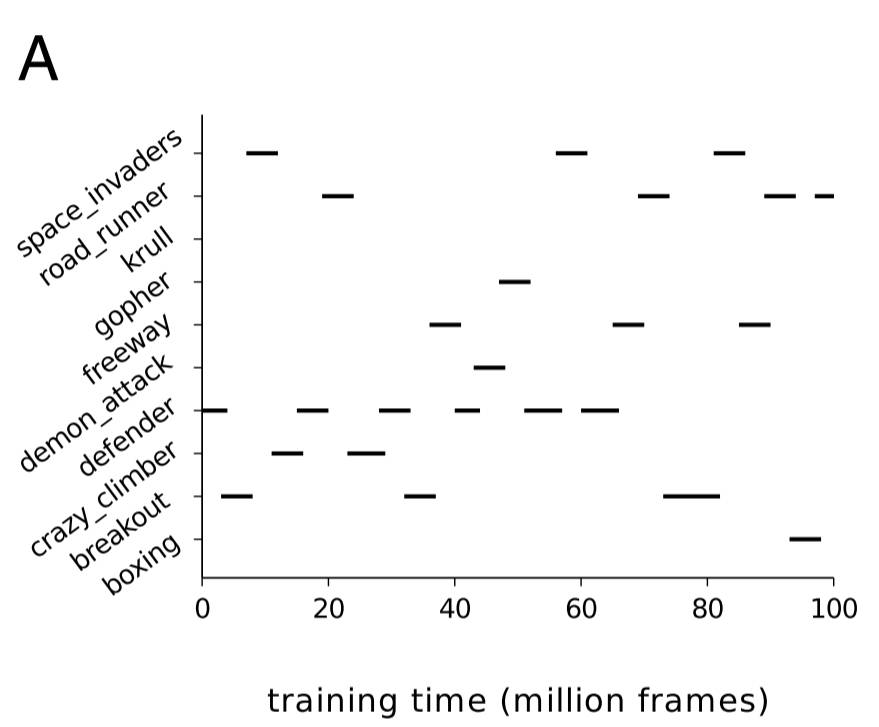
这就得到了一个能够跨两个时间尺度进行学习的 DQN 代理。在短期内,DQN 代理可以使用 SGD 等优化器(本案例中研究者使用了 RMSProp)来从经历重放(experience replay)机制中学习。在长期内,该 DQN 代理使用 EWC 来巩固其从各种任务上学习到的知识。研究者从 DQN 实现了人类水平表现的 Atari 游戏(共 19 个)中随机选出了 10 个,然后该代理在每个单独的游戏上训练了一段时间,如下所示:
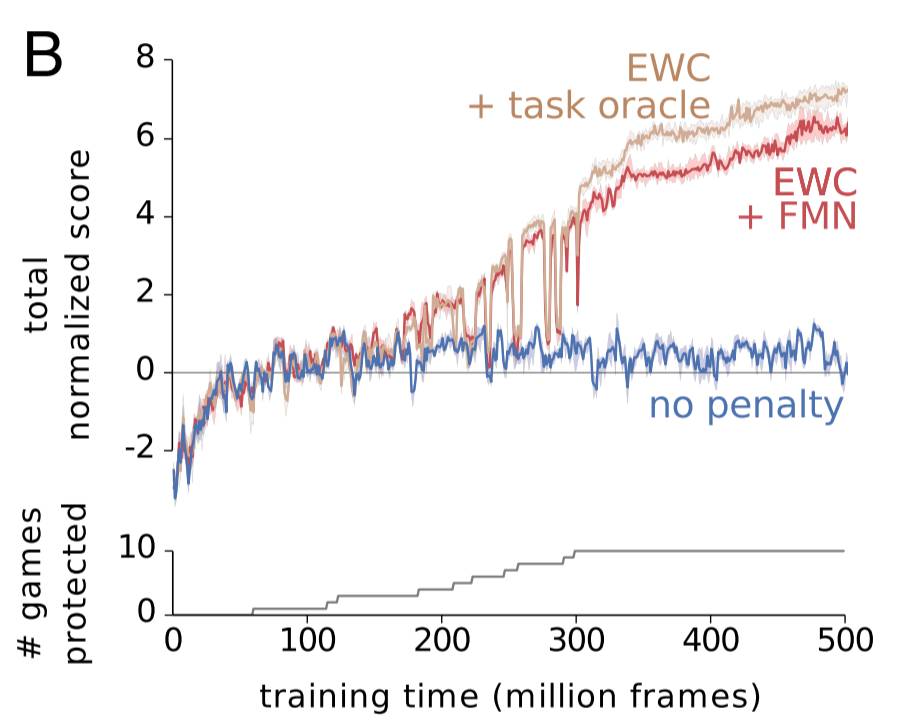
这些研究者对三个不同的 DQN 的代理进行了比较。蓝色代理没有使用 EWC,红色代理使用了 EWC 和 forget-me-not 任务标识符。褐色代理则使用 EWC,并被提供了真实任务标签。在一个任务上实现人类水平的表现被规范化为分数 1。如你所见,EWC 在这 10 个任务上都实现了接近人类水平的表现,而非 EWC 代理没能在一个以上的任务上做到这一点。该代理是否被给出了一个真实标签或是否必须对任务进行推导对结果的影响不大,但我认为这也表明了 FMN 过程的成果,而不仅仅是 EWC 的成功。
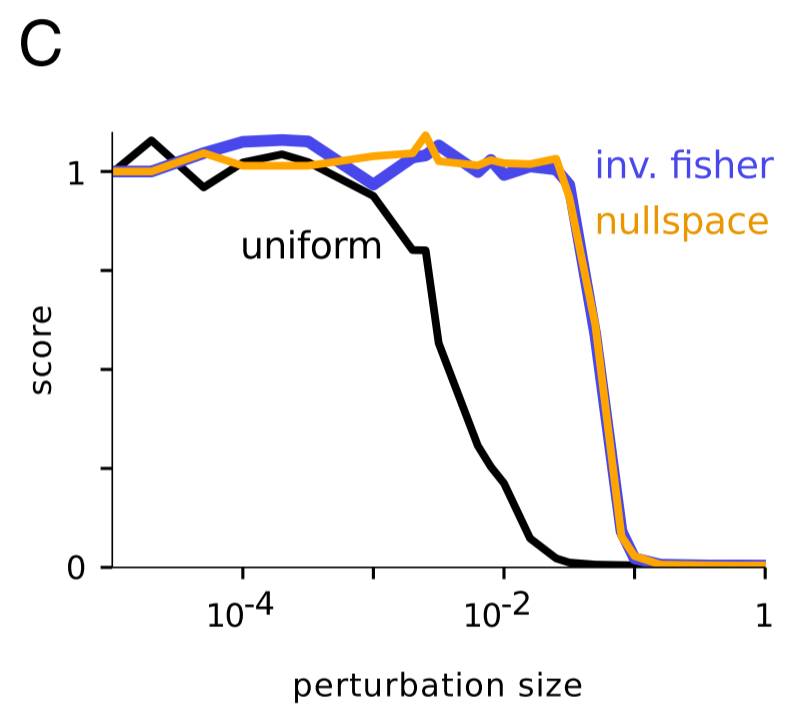
接下来的这个部分非常酷。如前所述,EWC 并没有在这 10 个任务上实现人类水平的表现。为什么会这样?一个可能的原因是 Fisher 信息矩阵可能对参数重要程度的估计不佳。为了实际验证这一点,这些研究者研究了在仅一个游戏上训练的代理的权重。不管这个游戏是什么游戏,它们都表现出了以下模式:如果权重受到了一个均匀随机扰动的影响,随着该扰动的增加,该代理的表现(规范化为 1)会下降;而如果权重受到的扰动得到了 Fisher 信息的对角线的逆的影响,那么该分数在面临更大的扰动时也能保持稳定。这说明 Fisher 信息在确定参数的真正重要性方面是很好的。
然后,研究者尝试在 null 空间中进行扰动。这本来应该是无效的,但实际上研究者观察到了与逆 Fisher 空间中的结果类似的结果。这说明使用 Fisher 信息矩阵会导致将一些重要参数标记为不重要的情况――「因此很有可能当前实现的主要限制是其低估了参数的不确定性。」
讨论
贝叶斯说明
作者们对 EWC 给出了非常好的贝叶斯解读:「正式来说,当需要学习新的任务时,网络参数被先验所调节,也就是先前任务在给定数据参数上的后验分布。这能实现先验任务被约束的更快的参数学习率,并为重要的参数降低学习率。」
网络重叠
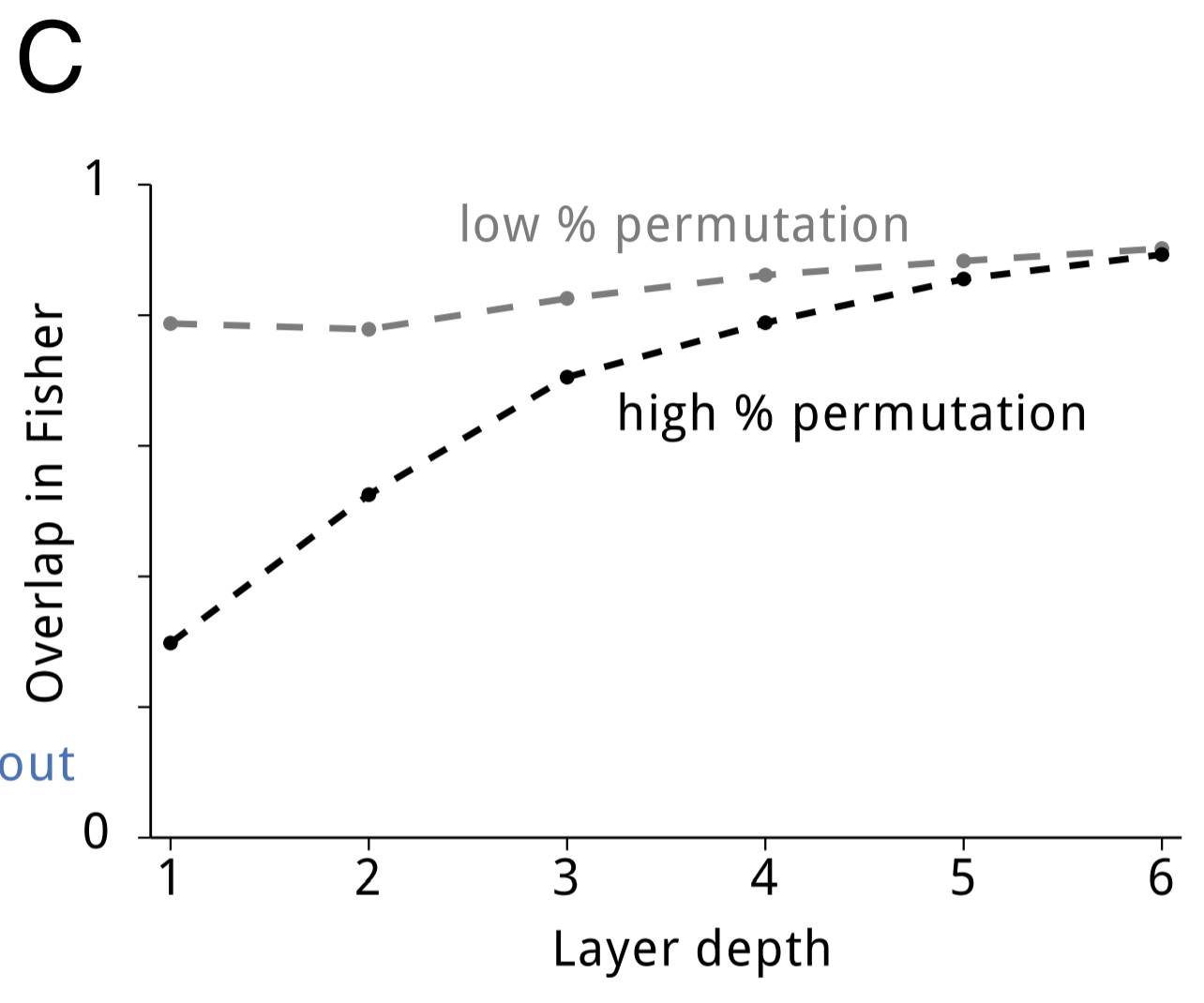
在刚开始时,我提到神经网络的过参数化(overparameterization)让 EWC 能实现优异的表现。有一个很合理的问题就是:为了每个不同的任务将网络划分到特定部分,这些神经网络能否给出更好的表现?或者通过共享表征,这些网络是否能高效地使用其能力?为了解答这个问题,作者们测量了任务对在 Fisher 信息矩阵上的重叠情况(Fisher Overlap)。对高度类似的任务(例如只有一点不同的两个随机排列)而言,Fisher Overlap 相当高。即使不相似的任务,Fisher Overlap 也高于 0。随着网络深度的增加,Fisher Overlap 也会增加。下图演示了该结果:
突触可塑性的理论
研究者还讨论了 EWC 可能能为神经可塑性方面的研究提供信息。级联(Cascade)理论企图构建突触状态的模型来对可塑性和稳定性建模。尽管 EWC 不能随时间缓和参数,也因此不能遗忘先前的信息,但 EWC 和级联都能通过让突触更不可塑而延展记忆稳定性。最近的一项研究提出除了存储自身的实际权重之外,突触也存储当前权重的不确定性。EWC 是该思路的延展:在 EWC 中,每个突触存储三个值:权重、均值和方差。
总结
没有遗忘的连续学习任务对智能而言很有必要;
研究表明哺乳动物大脑中的突触巩固有助于实现连续学习;
EWC 通过让重要参数变的更可塑,从而模拟人工神经网络中的突触巩固;
EWC 应用于神经网络时表现出了比 SGB 更好的表现,而且在更大范围上有一致的参数稳定性;
EWC 提供了说明权重巩固是连续学习的基础的线索证据。
转载请注明出处。
 相关文章
相关文章 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
