参与:吴攀、李泽南、李亚洲
前几天,Google DeepMind 公开了一篇新论文《克服神经网络中的灾难性遗忘(Overcoming catastrophic forgetting in neural networks)》,介绍了这家世界顶级的人工智能研究机构在「记忆(memory)」方面的研究进展,之后该公司还在其官方博客上发布了一篇介绍博客,参见机器之心的报道《》。近日,加利福尼亚大学戴维斯分校计算机科学工程和统计学的毕业生 Rylan Schaeffer 在其博客上发表了一篇对该研究的深度解读文章,机器之心对该文章进行了编译介绍,论文原文可点击文末「阅读原文」查看。
引言
我发现网络上铺天盖地的人工智能相关信息中的绝大多数都可以分为两类:一是向外行人士解释进展情况,二是向其他研究者解释进展。我还没找到什么好资源能让有技术背景但对不了解更前沿的进展的人可以自己充电。我想要成为这中间的桥梁――通过为前沿研究提供(相对)简单易懂的详细解释来实现。首先,让我们从《Overcoming Catastrophic Forgetting in Neural Networks》这篇论文开始吧。
动机
实现通用人工智能的关键步骤是获得连续学习的能力,也就是说,一个代理(agent)必须能在不遗忘旧任务的执行方法的同时习得如何执行新任务。然而,这种看似简单的特性在历史上却一直未能实现。McCloskey 和 Cohen(1989)首先注意到了这种能力的缺失――他们首先训练一个神经网络学会了给一个数字加 1,然后又训练该神经网络学会了给数字加 2,但之后该网络就不会给数字加 1 了。他们将这个问题称为「灾难性遗忘(catastrophic forgetting)」,因为神经网络往往是通过快速覆写来学习新任务,而这样就会失去执行之前的任务所必需的参数。
克服灾难性遗忘方面的进展一直收效甚微。之前曾有两篇论文《Policy Distillation》和《Actor-Mimic: Deep Multitask and Transfer Reinforcement Learning》通过在训练过程中提供所有任务的数据而在混合任务上实现了很好的表现。但是,如果一个接一个地引入这些任务,那么这种多任务学习范式就必须维持一个用于记录和重放训练数据的情景记忆系统(episodic memory system)才能获得良好的表现。这种方法被称为系统级巩固(system-level consolidation),该方法受限于对记忆系统的需求,且该系统在规模上必须和被存储的总记忆量相当;而随着任务的增长,这种记忆的量也会增长。
然而,你可能也直觉地想到了带着一个巨大的记忆库来进行连续学习是错误的――毕竟,人类除了能学会走路,也能学会说话,而不需要维持关于学习如何走路的记忆。哺乳动物的大脑是如何实现这一能力的?Yang, Pan and Gan (2009) 说明学习是通过突触后树突棘(postsynaptic dendritic spines)随时间而进行的形成和消除而实现的。树突棘是指「神经元树突上的突起,通常从突触的单个轴突接收输入」,如下所示:
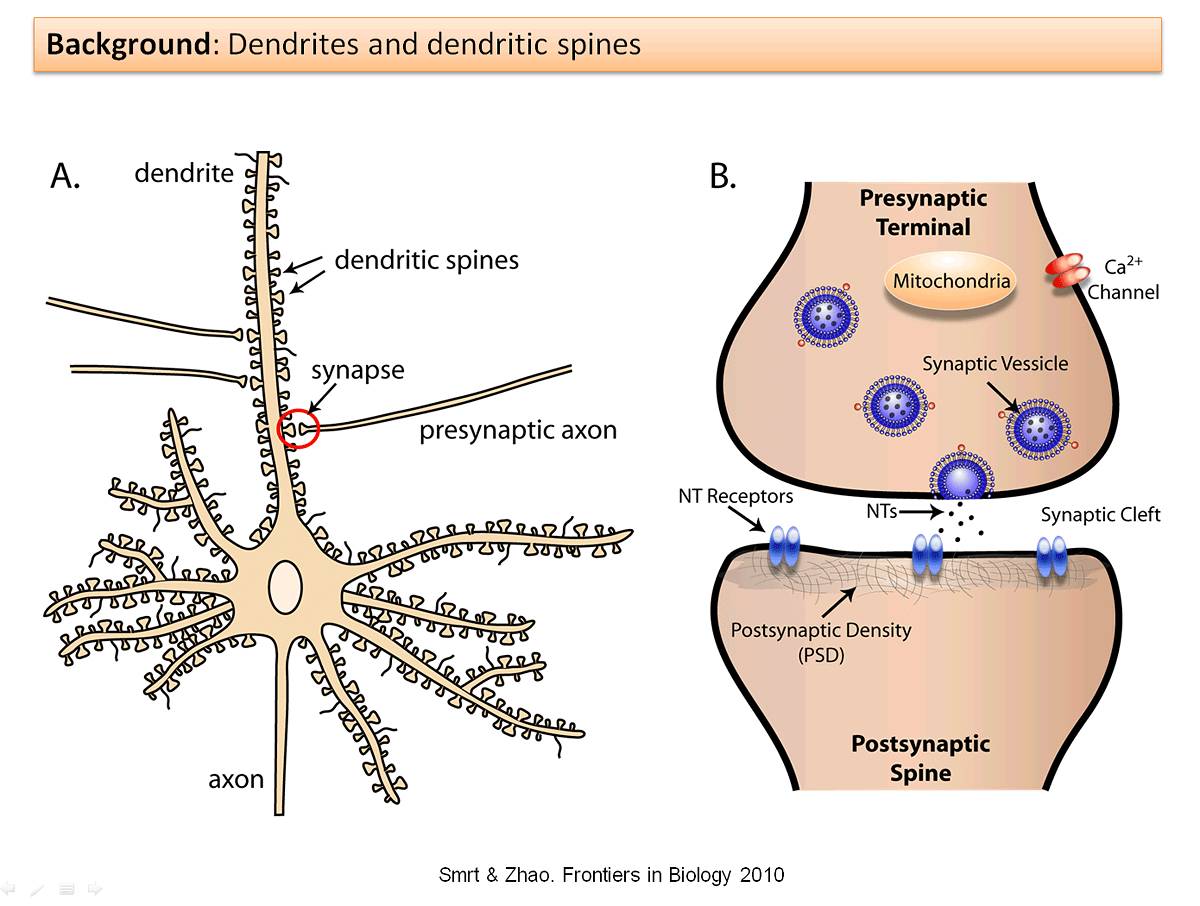
具体而言,这些研究者检查了小鼠学习过针对特定新任务的移动策略之后的大脑。当这些小鼠学会了最优的移动方式之后,研究者观察到树突棘形成出现了显著增多。为了消除运动可能导致树突棘形成的额外解释,这些研究者还设置了一个进行运动的对照组――这个组没有观察到树突棘形成。然后这些研究者还注意到,尽管大多数新形成的树突棘后面都消失了,但仍有一小部分保留了下来。2015 年的另一项研究表明当特定的树突棘被擦除时,其对应的技能也会随之消失。
Kirkpatrick et. 在论文《Overcoming catastrophic forgetting in neural networks》中提到:「这些实验发现……说明在新大脑皮层中的连续学习依赖于特定于任务的突触巩固(synaptic consolidation),其中知识是通过使一部分突触更少塑性而获得持久编码的,所以能长时间保持稳定。」我们能使用类似的方法(根据每个神经元的重要性来改变单个神经元的可塑性)来克服灾难性遗忘吗?
这篇论文的剩余部分推导并演示了他们的初步答案:可以。
直觉
假设有两个任务 A 和 B,我们想要一个神经网络按顺序学习它们。当我们谈到一个学习任务的神经网络时,它实际上意味着让神经网络调整权重和偏置(统称参数/θ)以使得神经网络在该任务上实现更好的表现。之前的研究表明对于大型网络而言,许多不同的参数配置可以实现类似的表现。通常,这意味着网络被过参数化了,但是我们可以利用这一点:过参数化(overparameterization)能使得任务 B 的配置可能接近于任务 A 的配置。作者提供了有用的图形:
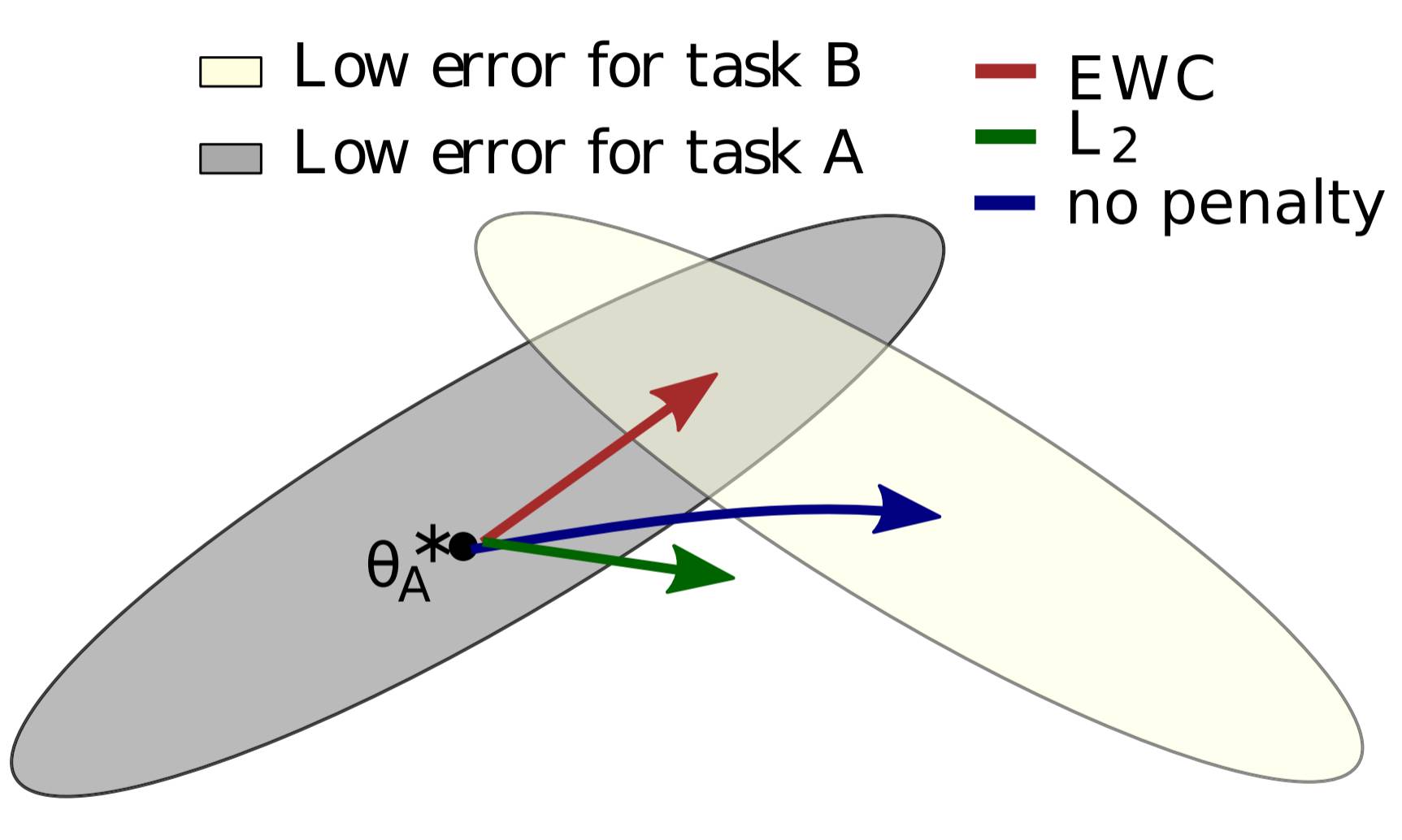
在图中,θ?A 代表在 A 任务中表现最好的 θ 的配置,还存在多种参数配置可以接近这个表现,灰色表示这一配置的集合;在这里使用椭圆来表示是因为有些参数的调整权重比其他参数更大。如果神经网络随后被设置为学习任务 B 而对记住任务 A 没有任何兴趣(即遵循任务 B 的误差梯度),则该网络将在蓝色箭头的方向上移动其参数。B 的最优解也具有类似的误差椭圆体,上面由白色椭圆表示。
然而,我们还想记住任务 A。如果我们只是简单使参数固化,就会按绿色箭头发展,则处理任务 A 和 B 的性能都将变得糟糕。最好的办法是根据参数对任务的重要程度来选择其固化的程度;如果这样的话,神经网络参数的变化方向将遵循红色箭头,它将试图找到同时能够很好执行任务 A 和 B 的配置。作者称这种算法「弹性权重巩固(EWC/Elastic Weight Consolidation)」。这个名称来自于突触巩固(synaptic consolidation),结合「弹性的」锚定参数(对先前解决方案的约束限制参数是二次的,因此是弹性的)。
数学解释
在这里存在两个问题。第一,为什么锚定函数是二次的?第二,如何判定哪个参数是「重要的」?
在回答这两个问题之前,我们先要明白从概率的角度来理解神经网络的训练意味着什么。假设我们有一些数据 D,我们希望找到最具可能性的参数,它被表示为 p(θ|D)。我们可以是用贝叶斯规则来计算这个条件概率。
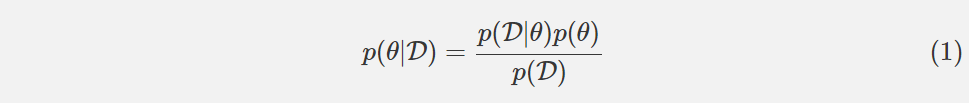
如果我们应用对数变换,则方程可以被重写为:
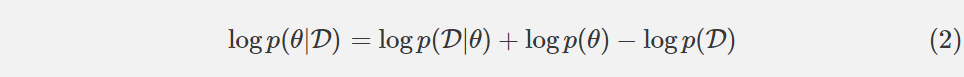
转载请注明出处。
 相关文章
相关文章 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
