假设数据 D 由两个独立的(independent)部分构成,用于任务 A 的数据 DA 和用于任务 B 的数据 DB。这个逻辑适用于多于两个任务,但在这里不用详述。使用独立性(independence)的定义,我们可以重写这个方程:
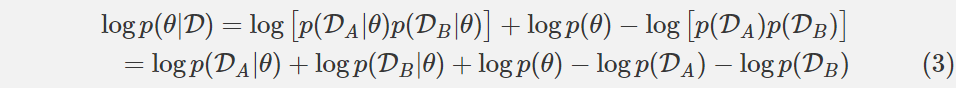
看看(3)右边的中间三个项。它们看起来很熟悉吗?它们应该。这三个项是方程(2)的右边,但是 D 被 DA 代替了。简单来说,这三个项等价于给定任务 A 数据的网络参数的条件概率的对数。这样,我们得到了下面这个方程:
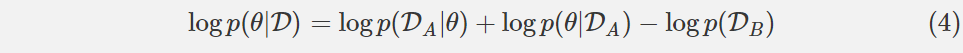
让我们先解释一下方程(4)。左侧仍然告诉我们如何计算整个数据集的 p(θ| D),但是当求解任务 A 时学习的所有信息都包含在条件概率 p(θ| DA)中。这个条件概率可以告诉我们哪些参数在解决任务 A 中很重要。
下一步是不明确的:「真实的后验概率是难以处理的,因此,根据 Mackay (19) 对拉普拉斯近似的研究,我们将该后验近似为一个高斯分布,其带有由参数θ?A 给定的均值和一个由 Fisher 信息矩阵 F 的对角线给出的对角精度。」
让我们详细解释一下。首先,为什么真正的后验概率难以处理?论文并没有解释,答案是:贝叶斯规则告诉我们
p(θ|DA) 取决于 p(DA)=∫p(DA|θ′)p(θ′)dθ′,其中θ′是参数空间中的参数的可能配置。通常,该积分没有封闭形式的解,留下数值近似以作为替代。数值近似的时间复杂性相对于参数的数量呈指数级增长,因此对于具有数亿或更多参数的深度神经网络,数值近似是不实际的。
然后,Mackay 关于拉普拉斯近似的工作是什么,跟这里的研究有什么关系?我们使用θ*A 作为平均值,而非数值近似后验分布,将其建模为多变量正态分布。方差呢?我们将把每个变量的方差指定为方差的倒数的精度。为了计算精度,我们将使用 Fisher 信息矩阵 F。Fisher 信息是「一种测量可观察随机变量 X 携带的关于 X 所依赖的概率的未知参数θ的信息的量的方法。」在我们的例子中,我们感兴趣的是测量来自 DA 的每个数据所携带的关于θ的信息的量。Fisher 信息矩阵比数值近似计算更可行,这使得它成为一个有用的工具。
因此,我们可以为我们的网络在任务 A 上训练后在任务 B 上再定义一个新的损失函数。让 LB(θ)仅作为任务 B 的损失。如果我们用 i 索引我们的参数,并且选择标量λ来影响任务 A 对任务 B 的重要性,则在 EWC 中最小化的函数 L 是:
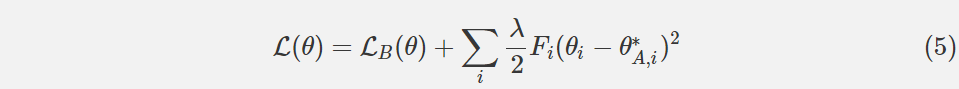
作者声称,EWC 具有相对于网络参数的数量和训练示例的数量是线性的运行时间。
实验和结果
随机模式
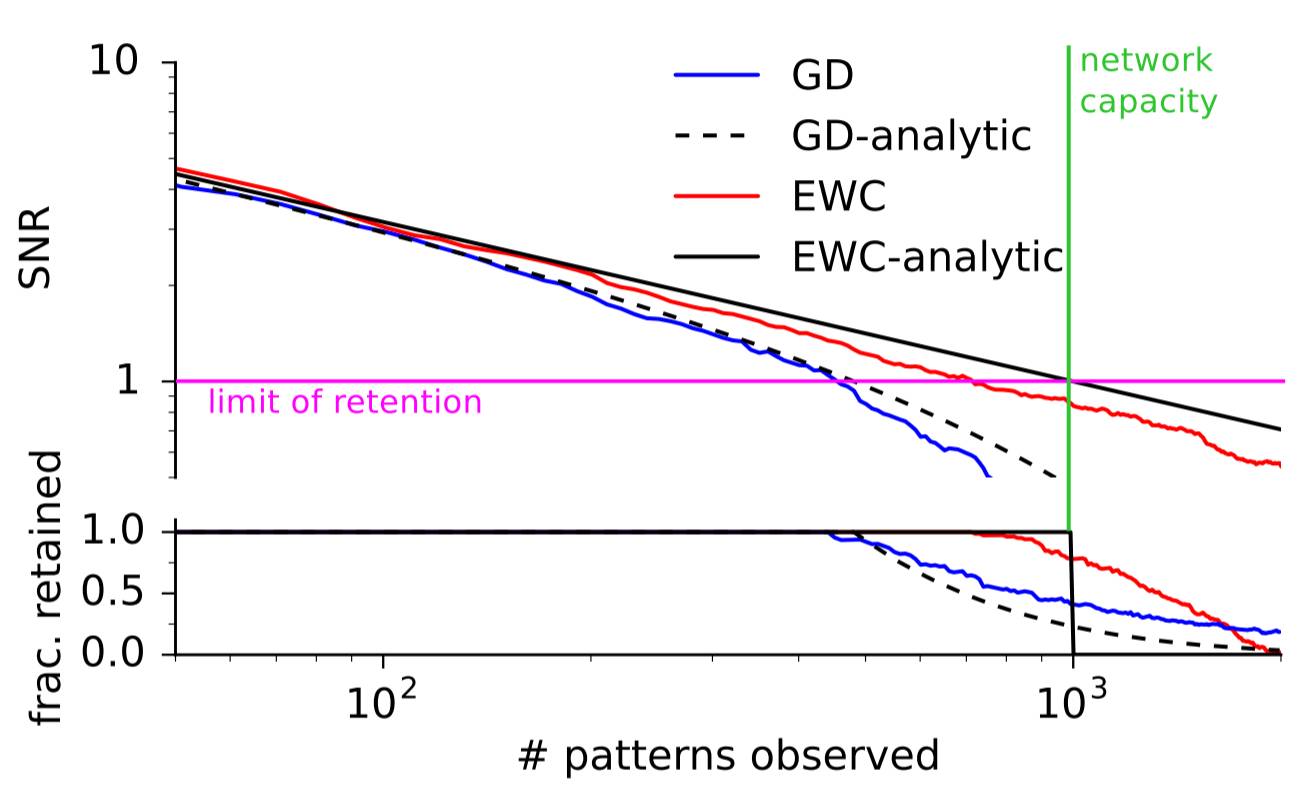
EWC 的第一个测试是简单地看它能否比梯度下降(GD)更长时间地记住简单的模式。这些研究者训练了一个可将随机二元模式和二元结果关联起来的神经网络。如果该网络看到了一个之前见过的二元模式,那么就通过观察其信噪比是否超过了一个阈值来评价其是否已经「记住」了该模式。使用这种简单测试的原因是其具有一个分析解决方案。随着模式数量的增加,EWC 和 GD 的表现都接近了它们的完美答案。但是 EWC 能够记忆比 GD 远远更多的模式,如下图所示:
MNIST
这些研究者为 EWC 所进行的第二个测试是一个修改过的 MNIST 版本。其没有使用被给出的数据,而是生成了三个随机的排列(permutation),并将每个排列都应用到该数据集中的每张图像上。任务 A 是对被第一个排列转换过的 MNIST 图像中的数字进行分类,任务 B 是对被第二个排列转换过的图像中的数字进行分类,任务 C 类推。这些研究者构建了一个全连接的深度神经网络并在任务 A、B 和 C 上对该网络进行了训练,同时在任务 A(在 A 上的训练完成后)、B(在 B 上的训练完成后)和 C(在 C 上的训练完成后)上测试了该网络的表现。训练是分别使用随机梯度下降(SGD)、使用 L2 正则化的均匀参数刚度(uniform parameter-rigidity using L2 regularization)、EWC 独立完成的。下面是它们的结果:
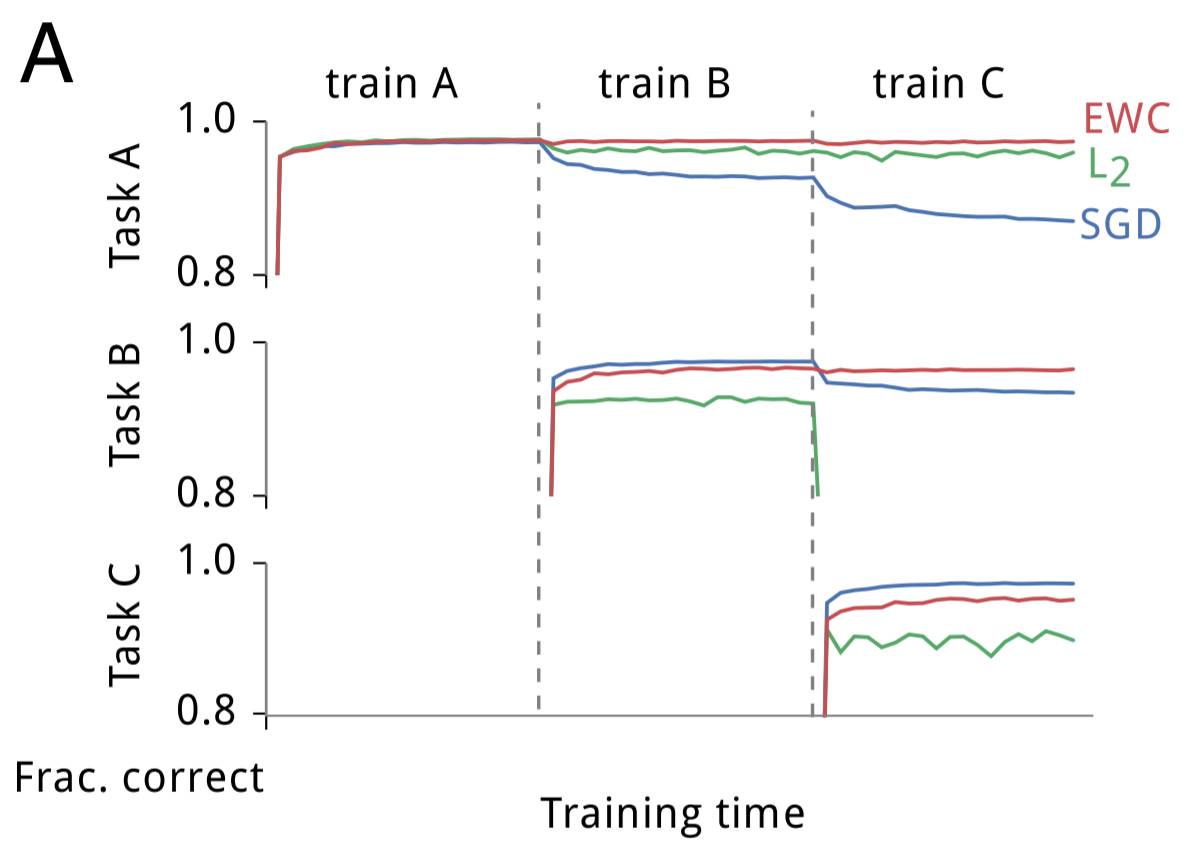
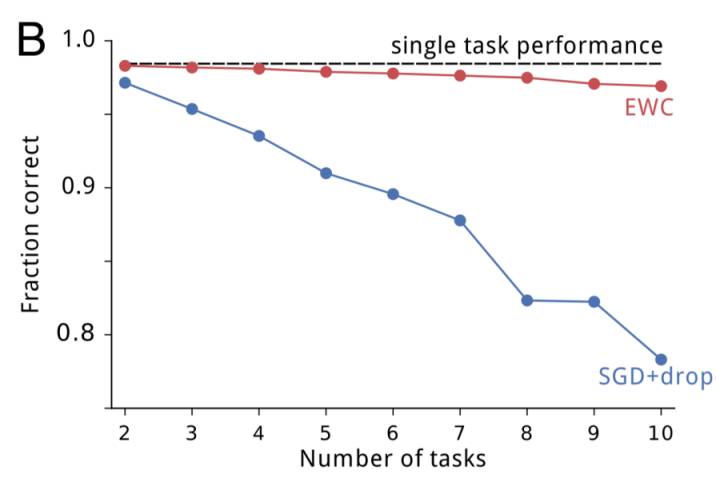
如预期的一样,SGD 出现了灾难性遗忘;在任务 B 上训练后在任务 A 上的表现出现了快速衰退,在任务 C 上训练后更是进一步衰退。使参数更刚性能维持在第一个任务上的表现,但却不能学习后续的任务。而 EWC 能在成功学习新任务的同时记住如何执行之前的任务。随着任务数量的增加,EWC 也能维持相对较好的表现,相对地,带有 dropout 正则化的 SGD 的表现会持续下降,如下所示:
Atari 2600
DeepMind 曾在更早的一篇论文中表明:当一次训练和测试一个游戏时,深度 Q 网络(DQN)能够在多种 Atari 2600 游戏上实现超人类的表现。为了了解 EWC 可以如何在这种更具挑战性的强化学习环境中实现连续学习,这些研究者对该 DQN 代理进行了修改,使其能够使用 EWC。但是,他们还需要做出一项额外的修改:在哺乳动物的连续学习中,为了确定一个代理当前正在学习的任务,必需要一个高层面的系统,但该 DQN 代理完全不能做出这样的确定。为了解决这个问题,研究者为其添加了一个基于 forget-me-not(FMN)过程的在线聚类算法,使得该 DQN 代理能够为每一个推断任务维持各自独立的短期记忆缓存。
转载请注明出处。
 相关文章
相关文章 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
