网络分为三个部分:编码器E、解码器D和风格库(style bank)K。输入图像I经过编码器编码为特征图(feature map)F,接着分为两路:下侧的实线箭头代表自编码器支路,F不经过风格库处理,直接经过解码器解码,得到O,O应该与I相似;上侧的虚线箭头代表风格化支路,F经过代表第i种风格风格库Ki滤波后得到特征图Fi,再经过D解码为风格化后的结果Oi。
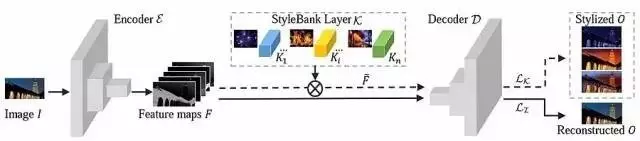
图1. 网络分为3部分:编码器E、风格库K和解码器D。
这篇文章的作者认为,目前的前馈网络之所以每次只能描述一种风格,是因为这些网络并没有完全将图像的内容和风格区别开来。为了解决这个问题,作者借鉴了传统纹理合成方法中纹理基元(texton)的概念,将纹理基元通过深度网络学习并存储在滤波器组中,作者称之为风格库(style bank),每类风格生成一个与之对应的风格库。在前向传播时,只需选择需要的风格库,就能完成指定风格的迁移,结合了快速和风格多样化两种优势。这些风格库建立在自编码器提取的特征空间基础上,能更好地描述每类风格。同时,自编码器与风格库的结合还具有易于扩展的优势:对于新的风格,只需要训练新的风格库,不必重新训练整个网络。最后,因为内容与风格有效分离,训练得到的自编码器能对图像内容进行有效的区域划分,实现了基于区域的风格化。
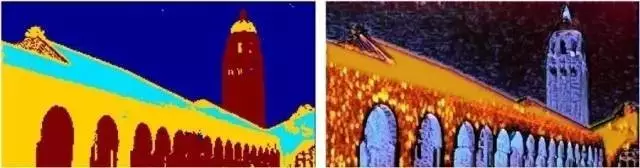
图2.左:编码得到的feature map的聚类结果。右:风格化结果。

图3. 两种风格的融合。
经过实验,作者发现:
每种风格的纹理基元被风格库中特定少数几个滤波器编码;
Style bank的滤波器半径越大,其能够描述的风格纹理尺度也越大;
自编码器将内容图像基于区域编码,同一区域会被同一类纹理风格化(见图2);
颜色风格和纹理风格分离:无纹理区域风格化后依然无纹理,不同纹理的同色区域将被风格化为不同纹理的同色区域,不同色的相同纹理被风格化为不同色的相似纹理;
对多个风格库进行加权可以实现不同风格的融合(见图3),对编码结果使用不同的mask并作用于不同的风格库可以实现为不同区域迁移不同的风格。

图4.与基于迭代优化的方法[1]进行比较。从左至右:输入图像,本文结果,[1]的结果

图5.与基于前馈网络的方法[2]进行比较。从左至右:输入图像,本文结果,[2]的结果
[1] Gatys L A, Ecker A S, Bethge M. Image style transfer using convolutional neural networks. CVPR, 2016.
[2]Ulyanov D, Lebedev V, Vedaldi A, Lempitsky V. Texture networks: Feed-forward synthesis of textures and stylized images. ICML, 2016.
论文地址:http://www.ganghua.org/publication/CVPR17f.pdf
单纯“刷分”是将研究机械化和暴力化,但为了PR刷分可以理解,但不提倡
在CV领域有各类竞赛,“刷分”现象普遍存在,业界对此褒贬不一。您对“刷分”怎么看?
首先,我自己从来不做单纯“刷分”的事情,也基本不参加所谓的竞赛。研究成果,归根结底,是说你有没有为这个领域提供新的知识。所以,“刷分”应该是作为验证你的研究的一种“手段”,而不是最终目的。研究和评审过程中唯“分数”论,都是将研究机械化和暴力化,是不值得提倡的。不过,刷分做宣传那又另当别论了,可以理解,但我自己是不会做的。当然,我所指的单纯刷分是指你在刷分过程中并没有对问题的理解提供新的知识,也没有为领域发展开拓新的方法,打个比如说,我集成了10个最好的模型,当然会取得最好的结果。但是,集成这10个模型的方法算不算创新――集成也是需要技术的――有没有给学界带来新的知识呢?如果你的集成方法是大多数时候圈内人都知道怎么做的,只是不屑于做罢了,那样的刷分,是机械的,暴力的,是没有多少价值的。
在迭代如此快速、深度学习不断刷新各种性能的情况下,微软各研究院的研究人员如何从事“有意义/价值”的研究?如何产出高质量的论文(不被其他人抢先发表)?
在微软,我们有一个研究的周期(cycle),在选题(研究方向)、实验等各个环节,花费时间和精力最更多的其实是在选题上。2001年我还在西安交通大学读研究生的时候,沈向洋博士到学校做了一个报告,当时他提到:最好的研究员发现新问题,好的研究员创造新方法解好问题,一般的研究员跟随别人的方法解问题。也就是说,创新是研究的本质,只要你把问题或者方向想清楚、想透彻了,别人还是很难catch up的。当然,你说的被人抢先发表的情况偶尔也会有,那就是执行力的问题了。
微软研究院软件工程研究(RiSE)组研究经理Thomas Ball在今年,也是他进入微软第17年写下的文章《微软研究院的产业研究周期》(Microsoft Research and the industrial research cycle),介绍了微软研究院的Research Cycle。
计算机视觉发展:AI各子领域合久必分,分久必合
此前采访李开复老师,他提到优秀企业的稀缺造成资本过度追逐,仅做人脸识别的初创公司估值接近独角兽不合理。李开复还预计一年后计算机视觉会出现一个短暂的寒冬。您认为单做人脸识别的创业公司价值如何?一年之后计算机视觉会迎来短暂的寒冬吗?
我尊重李开复老师的看法,但我持比较中立的态度,主要是我对这些创业公司的具体业务细节并不是很了解。单从技术角度说,计算机视觉发展这么多年,作为一项生物识别技术,在图像识别、金融、安防等很多领域技术已经成熟,到了可以商业应用的阶段。我对计算机视觉商业化一直有自己的兴趣,最近也进行了一些深入的思考。在微软计算机视觉多年积累的基础上,我今后的工作有一部分也会关注将相关技术产品化,参与相关商业化策略的制定和整合上面。
转载请注明出处。
 相关文章
相关文章 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
