这3点的排列也是由易到难,基于“任务”就是理解有一个明确的目标,而基于“知识”则是知道该怎么去做这件事。打个比方,两者的区别就像是知道了“授人以鱼”和“授人以渔”中的“鱼”和“渔”。总之,最终的目标都是朝着一个综合、集成的智能系统去服务。
作为CVPR 2017领域主席:很高兴看到更多的反思深度学习机制的论文出现,CMU运动姿态论文印象深刻
您是这届CVPR的领域主席(area chair)。现在CVPR 2017接收论文已确定,能透露一下这届会议从论文中体现出了什么趋势吗,果然深度学习、神经网络还是关键词?有什么其他亮点吗?
这届CVPR,我是领域主席,每个领域主席可以选择自己感兴趣和负责的研究议题(topic)――我的研究兴趣和研究方向比较广,所以大概覆盖了30多个topic中的10多个,我在评审过程中全权负责的论文有三四十来篇,加上评议圆桌讨论和别的领域主席复议的论文,了解到的论文大约只占最后全部接收论文的1/6~1/5。令人欣喜的是,这届CVPR涌现了很多结合领域知识(domain knowledge)尝试去理解、去反思深度学习机制的论文。不过,让我现在谈CVPR 2017的整体论文体现了什么趋势、有什么亮点,这还得等到会议开始后才能知道。
那在您所了解的范围内,有什么研究让您印象特别深刻吗?
CMU有一篇估计运动姿态的论文,里面的Demo给我们领域主席圆桌讨论复议时留下了非常深刻的印象,实现了多线程的多人关键点实时检测,将同一个视频里很多人的运动姿态都同时捕捉下来。这篇论文也是CVPR 2017口头汇报的论文之一,其代码赢得了2016年MSCOCO关键点挑战赛以及2016年ECCV最佳演示奖。论文提出了一种自下而上的方法进行多人姿态估计,而不需要任何行人检测的算法。

摘要
我们提出了一种有效地检测图像中多个人 2D 姿态的方法。该方法使用非参数表征,我们将其称为部分亲和字段(PAF),能够学习将身体部分与图像中的个体关联起来。该架构对全局环境进行编码,允许一个贪心的自下而上的解析步骤(parsing step),保持高精度的同时,实现实时性能,无论图像中的人数有多少。这一架构旨在通过同一个顺序预测过程的两个分支,联合学习局部位置及其关联。我们的方法在 COCO 2016 关键点挑战赛中取得了第一名,与 MPII MultiPerson 基准此前最好的结果相比,我们的方法在性能和效率上都高出很多。
另外,我也简单介绍一下微软的工作。微软这次被CVPR接收的论文一共有30篇左右,跟我们在过去15年来每年在CVPR上发表的论文数大体相当,其中微软亚洲研究院有18篇,各个方向都有,3D建模,计算摄影,图像视频分析、理解、分割……覆盖率还是比较广的。其中一项视频人脸识别方面的研究,将视频中每一帧的人脸都提取出来,得出一个紧凑的固定长度的表征,更快更精确的进行人脸识别。

摘要
本文提出了一种用于视频人脸识别的神经聚合网络(Neural Aggregation Network,NAN)。网络将一个人脸部的视频或者一组数量不同的脸部图像数据集作为输入,并且生成一个紧凑(compact)、维度固定的特征表征,可用于识别。整个网络由两个模块组成。特征嵌入模块是一个深度卷积神经网络(CNN),它将每幅人脸图像都映射成一个特征向量。聚合模块由两个注意力模块(attention block)组成,它们能够自适应地聚合特征向量,在它们所覆盖的凸包(convex hull)中形成单个特征。由于注意力机制,聚合不会因图像顺序的变化而发生改变。我们的 NAN 由一个标准分类或验证损失训练,没有接收任何额外的监督信号,但我们发现它能够自动学习优选(advocate)高质量的脸部图像,同时排除(repel)低质量的图像,比如模糊、有遮挡和姿态不端(improperly exposed)的面部图像。在 IJB-A、YouTube Face、Celebrity-1000 视频脸部识别基准测试的实验表明,NAN 始终优于朴素聚合方法,并且实现了当前最高的精度。
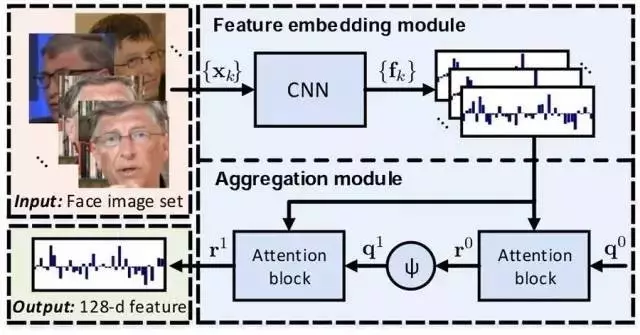
图1. NAN视频面部识别的网络架构。所有输入面图像{xk}由具有深度CNN的特征嵌入模块处理,产生一组特征向量{fk}。接着这些特征被传递到聚合模块,产生单个128维向量r1表示输入的人脸图像。这种紧凑的表征(compact representation)可用于识别。

图6. YTF数据集上的典型示例,显示了我们的NAN计算的视频每帧的权重。每一行表示从视频采样5个帧,并根据其权重(图片左上角矩形中的数字)进行排序; 最右边的条形图显示所有帧的排序权重(高度缩放)。
http://www.ganghua.org/publication/CVPR17e.pdf
另一项是图像风格化的工作,这是第一次对图像风格做出了明确的物理和数值表征,我们能够将风格表征和图像内容分离出来,因此能用一个网络做很多不同的风格。现在学习一个风格只需要8分钟,转换的话只要几秒,我们正在把这个技术用应用到微软的产品中间去。

根据CCF多媒体技术专委会新技术选介17-04期的介绍,该论文采用了自编码器与滤波器组(filter bank)相结合的结构,能够同时对多种风格进行学习,将不同风格存储到各自对应的filter bank中,从而只使用一个前馈网络就能进行多种风格的迁移。
转载请注明出处。
 相关文章
相关文章 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
