1. 本文的模型相比于 Attentive Reader 和 Impatient Reader 更加简单,没有那么多繁琐的 attention 求解过程,只是用了点乘来作为 weights,却得到了比 Attentive Reader 更好的结果,从这里我们看得出,并不是模型越复杂,计算过程越繁琐就效果一定越好,更多的时候可能是简单的东西会有更好的效果。
2. 文中直接利用 attention 机制选择答案,模型就比较偏爱出现次数多的词,这就隐含了出现次数比较多的词作为答案的可能性大的假设,所以从根本上本文是基于 task 的研究而不是从理论出发的。
简评摘录于西土城的搬砖日常的[知乎文章](https://zhuanlan.zhihu.com/p/23462480#!),这篇文章上还有详细的本论文相关模型的分析,推荐大家读一下。
完成人信息
李宸宇 chenyu.li@duke.edu
实录
问:文章的答案都是从文本中找,那如果答案是一句话呢,或者说是我们常见到的从四个句子里选一个,那么效果是否会怎么样,如果说从在模型后边接一个生成模型,就是文中的模型选出关键字,然后利用这些关键字来生成一个句子,会不会更好一些?
答:你说的很对,这篇文章所做的任务就是给答案的一部分然后从里面扣掉一个词 模型的目的是从原文中找出这个词,答案是一句话的这篇文章没有涉及,你说的先预测关键字再生成句子可能效果会不错 就是可能要分两步训练模型 一个用来预测关键字 一个用关键字生成句子,在生成句子的时候也可以将文章的信息和问题的信息通过特征向量引入模型 具体模型怎样设计 实验效果如何还是要做实验才可以知道。
问:模型介绍有一点和论文的描述有出入我帮忙强调下,对 document 的 embedding 和对 query 的 embedding 是不同的,对 document 每个 word 都 embed 成 vector,而 query 整体 embed 成一个 vector 相应的后续的 concat 两者也会有些差异。
答:可能我在写 note 的时候没有写清楚 所有的句子都是要先把每一个单词 embed 到 vector,再用 gru 进行 encode(编码),然后对于文本中的单词,双向 gru 在当前词输出拼在一起成为这一个词的新的向量表示,对于问题直接用双向 gru 最后的输出拼接作为问题的向量表示,最后用这两组向量进行接下来的运算,这是这篇文章的做法。
问:关键字生成模型――这个很难吧,context 缺乏啊:用文档 D 做 context 还是 Query 改写呢?
答:我的想法是可以采用原来语料库里面的数据 自己构建一个关键字字库,训练一个模型使用真正的关键字生成句子,然后将两个模型拼接在一起,然后根据原来语料库+答案关键字 生成答案句子?
问:我现在在做机器人,对 Q&A 感兴趣。“Attention sum reader network 的核心思想是通过注意力机制的权重计算出哪个词为答案词汇。”这句话能再解释下吗?我是个初学者,不太明白。
答:因为 attention 一开始的时候是先用一套机制算出每一个词向量的权重,然后用权重乘词向量的和作为最后的文本表示 在这里只需要算出每个词的权重 把相同词的权重加在一起 得到权重最高的词就是答案。
?
Neural Machine Translation with Reconstruction
论文链接:
https://arxiv.org/pdf/1611.01874v2.pdf
作者
Zhaopeng Tu, Yang Liu, Lifeng Shang, Xiaohua Liu, Hang Li
单位
Noah's Ark Lab, Huawei Technologies; Tsinghua University
关键词
NMT, autoencoder, reconstructor, reranking
文章来源
AAAI 2017
问题
在传统 attention-based NMT model 上增加一个 reconstructor 模块,用 auto-encoder 的思路,使得 source sentence 翻译之后的 translation 能够重建出 source sentence,改善翻译不充分的问题(over-translation/under-translation)。
模型
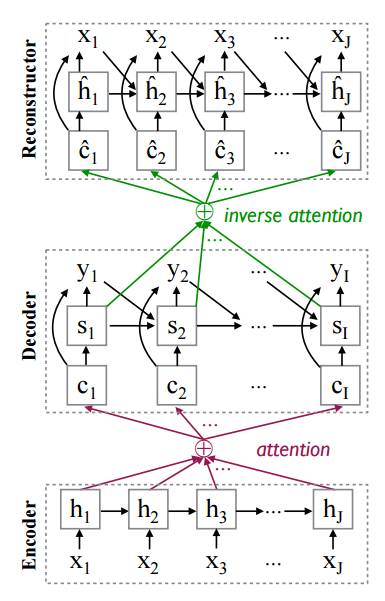
现有的 NMT 模型容易出现重复翻译以及部分词语未翻译的情况,因此翻译不够充分;同时在做 decoding 的时候根据 likelihood 去搜索最好的翻译句子并不是一个很好的方法,实验表明 likelihood 倾向于短的句子,在 beam search 时如果把 beam size 不断变大,那么 search 出来最后选择的句子会很短,bleu 就会很差。为了改善上面的两个问题,这篇文章提出用一种 autoencoder 的思路,希望用 decoder 的 hidden 尽可能地重建出 source 的词语,那么 decoder 所 embed 的信息就是相对丰富的,也能得到更好的翻译。其实就是给 NMT 一个更强的约束,而这个约束也非常合理,和 semi-supervised learning for NMT 出发点非常类似。
模型非常简单,直接上图,增加的 reconstructor 模块和 decoder 长的一样:
转载请注明出处。
 相关文章
相关文章 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
