答:这主要是因为二维表中的词语采用随机初始化的分配方式,随机分配的如果不合适的话,同一行词语之间彼此毫无语义关联,会使模型在预测下一个词行数的时候就产生较大分歧,导致了第一轮训练困难的情况。因此,第一次分配二维表中的词语时,或许可以提前采用一些手段做些预处理。类似于用预训练的 word embedding 来聚类,把同一类的词分配在同一个行里。或者用一些 Topic Model 把相同主题的词语分配在同一行,都有可能加快训练过程。其他的地方,例如重分配词语位置的方法,以及行列向量的组合方式等都有可能有改进的空间,这些地方我目前还没有太好的想法,大家等下自由交流阶段也可以多提提自己的想法 。
问:在词表很大的情况下,也就是说无法在内存当中存下每个词在词表中的概率的情况下,怎么高效地重分配词表呢,分配词表的算法不取全局最优解对最终的影响估计有多大呢,有没有什么形式化的表示可以说明影响的大小呢 ?
答:实际上我之前也想过这个问题,因为在重分配的过程中,每个词在词表的概率占用的空间还是很大的,是 O(V^2)。不过相对于显存来说,鉴于内存实在是比较便宜,这个问题的影响一般应该不大。内存如果放不下而采用从硬盘读写的方法,应该会极大地降低模型训练速度,反倒得不偿失。而重分配过程中,实际上分配词表的方法一直都不是最优解。首先本文采用的是一个 1/2 近似的 MCMF 算法,并不能达到最优解。其次,本文中的优化目标函数实际上也并不能真正的使模型在固定 Embedding 的情况下,Loss 最小。因为本文一直基于一个假设,便是每次只改动一个词语的位置,计算对应的 Loss。而当所有位置都变化的情况下,前文的表示已经改变,也不能再用之前已经训练好的 RNN 的状态来计算 loss 了。这也是我之前说的,重分配词语位置的方法还可以改进的原因,但对于具体的改进方法,目前我还没有什么好的想法。欢迎大家等一下详细来讨论。
问:这篇文章的做法是将一个词拆分成一个 table 中的行列向量的表示,并分别预测行部份和列部分,那如果我将一个词表示成 table 中行列向量的拼接,一次性地预测和输入,效果会怎样呢,在实验前有没有一些理论上的依据可以评估呢。
答:这是我之前提到的另一个改进的可能了,改进行列向量的组合方式。你提出的这种方法,输出预测部分,将输出的结果分割,然后分别预测行列号。在没有实验之前,很难评价效果是好是坏。但是我个人不是很认可这种处理方式。因为这样缺少了一步我觉得比较关键的过程,即通过前文和行来预测列。行列交替预测有两个优点,一个是缩小搜索空间。另一方面是可以通过词语重分配使相近词语处于同一行,增强 rare word 的表示能力。
问:行列组合生成 word embedding 的做法是否可以扩展为更高维,例如 3 维(行、列、层)的 Embedding Component 组合?感觉可以进一步压缩 Embedding 体积。
答:本文作者虽然也提到了这种可能性,即用 3 维的组合。但是我个人也不看好这种方法。实际上,我最近也在尝试用二维的组合方式来训练语言模型,模型非常难以收敛,只有一个好的词表分配方法才能使模型达到比较好的效果,而我们采用三维的组合方式,减少了模型的复杂度,会让模型更加难以训练。应该说,减少了模型的参数,很难说现实中有一种很好地词表组合方式,使模型训练的很好。
?
Text understanding with the attention sum reader network
论文链接
https://arxiv.org/abs/1603.01547
作者
Rudolf Kadlec, Martin Schmid, Ondrej Bajgar, Jan Kleindienst
单位
IBM Watson
关键词
Machine Reading Comprehension
文章来源
ACL2016
问题
针对 context―question-answer 数据集,使用注意力机制直接在原文本上获取问题的答案。网络结构简单, 计算量小,并取得 state of the art 的结果。
模型
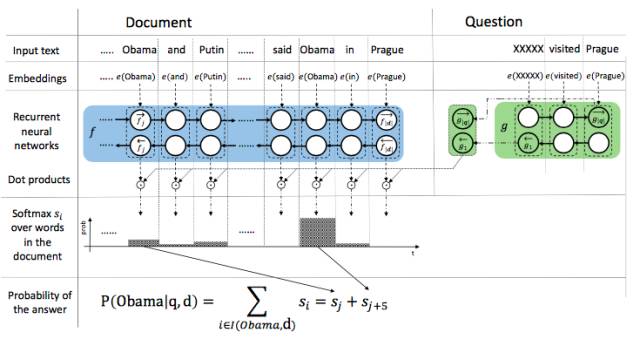
Attention sum reader network 的核心思想是通过注意力机制的权重计算出哪个词为答案词汇。如上图所示,在使用 embedding 将文本和 query 中的词分别映射成向量之后,使用单层的双向 GRU 将文本中的词编码,每个 time step 两个方向编码的拼接来代表当前 time step 的词的向量。使用另一个单层双向 GRU 对 query 进行编码,两个方向最后一步输出拼接为 query 的编码向量。
将每一个词的向量表示与 query 的向量点积,之后归一化得到的结果作为每一个词的注意力权重,同时将相同词的权重合并。最后每个词的权重即为答案是这个词的概率,最大概率的词就是答案。在实际计算过程中,只选择了候选答案中的词进行计算,因此减少了计算量。
从结果上来看,论文发表时模型在 CNN/Daily Mail 和 CBT 的数据集上取得了 SOTA 的结果。
资源
[CBT dataset]
[AS Reader implementation]
https://github.com/rkadlec/asreader
相关工作
Attentive and Impatient Reader
1. Teaching machines to read and comprehend
2. A Thorough Examination of the CNN / Daily Mail Reading Com- prehension Task
Memory Networks
The goldilocks principle: Reading children’s books with explicit memory representations
Dynamic Entity Representation
Dynamic Entity Representation with Max-pooling Im-proves Machine Reading
Pointer Networks
Pointer Networks
简评
转载请注明出处。
 相关文章
相关文章 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
