2. 我们有 2 种方式来控制图像表示。没有条件性 GAN,所有的图像信息都被编码在 Z 中。有了 cGAN,当我们添加条件信息 Y 时,现在这两个 Z 和 Y 将编码不同的信息。例如,假设 Y 编码手写数的数字(从 0 到 9)。然后,Z 将编码所有不在 Y 中编码的其它变量。例如,可以是数字的样式(大小、重量、旋转等)。

MNIST 样本上 Z 和 Y 之间的差异。Z 固定在行上,Y 在列上。Z 编码数字的样式,Y 编码数字本身。
最近的研究
有很多关于这个主题的有趣文章。我重点说这其中的两个:
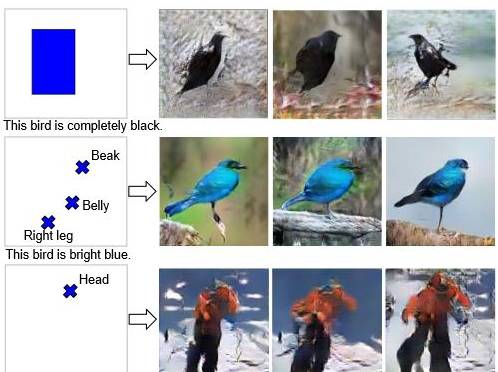
学习画什么和在哪里画 [文章](链接:https://arxiv.org/abs/1610.02454)[代码](链接:https://github.com/reedscot/nips2016):在这篇文章中,作者提出了一种机制来告诉 GAN(通过文本描述),(a)你想要得到的图像内容是什么样,(b)通过边界框/地标来告知元素的位置。看看它的生成结果:
StackGAN [article](链接:https://arxiv.org/abs/1612.03242)[code](https://github.com/hanzhanggit/StackGAN):这篇文章与前一篇相似。在这种情况下,他们专注于通过同时使用 2 个 GAN 来提高图像的质量:Stage-I 和 Stage-II。Stage-I 用于获取包含图像「一般」构想的低分辨率图像。Stage II 采用更多的细节和更高的分辨率来优化 Stage-I 的图像。据我所知,这篇在生成高质量图像里是最好的模型之一。请自己看:

你也许想要使用条件性 GAN,如果:
你有一个已标记的训练集,并希望提高生成图像的质量。
你想要明确控制图像的某些方面(例如,我想在这一特定位置生成这一尺寸的红鸟)。
InfoGANs
TL; DR:能够以无监督的方式在噪声向量 Z 的一部分中编码有意义的图像特征的 GAN。例如,对一个数字的旋转进行编码。
[文章](https://arxiv.org/abs/1606.03657)
你有没有想过输入噪声 Z 在一个 GAN 中编码的信息是什么?它通常以非常「嘈杂」的方式编码图像不同类型的特征。例如,你可以选择 Z 向量的一个位置,并将其值从 -1 和 1 插值。这是你会在一个通过 MNIST 数字数据集训练的模型上看到的:

对 Z 插值。左上图像的 Z 位置设置为 -1。然后,它被内插到 1(右下图像)。
在上图中,生成的图像看上去像是数字 4 慢慢变换成「Y」(最可能的是 4 和 9 之间的混合)。所以,这就是我所指的通过嘈杂的方式编码这个信息:Z 的单一位置是图像多个特征的参数。在这种情况下,这个位置改变了数字本身(某种程度上从 4 到 9)和样式(从粗体到斜体)。然后,你无法定义 Z 的该位置的任何确切含义。
如果我们可以有一些 Z 的位置来表示唯一和受限的信息会怎么样呢,就像 cGAN 中的条件信息 Y 一样?例如,如果第一个位置是一个 0 到 9 之间的值,它来控制数字的数量,而第二个位置控制其旋转,这会怎样呢?这正是作者在文章中提出的。有意思的部分是,与 cGAN 不同,他们以无监督的方式实现了这一点,无需标签信息。
将 Z 矢量分成两部分――C 和 Z――是他们成功的原因:
C 对数据分布的语义特征进行编码。
Z 编码该分布的所有非结构噪声。
转载请注明出处。
 相关文章
相关文章 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
