参与:赵华龙、黄小天
你是否曾经想了解生成对抗网络(GAN)?也许你只是想赶时髦?或者也许只想看看这些网络在过去几年中的改进?那么在这些情况下,你没准会对这篇文章感兴趣!
本文不涉及的内容
首先,你不会在本文中发现:
复杂的技术说明
代码(尽管有为那些感兴趣的人留的代码链接)
详尽的研究清单(点击这里进行查看 链接:)
本文涉及的内容
关于 GAN 的相关主题的总结
许多其他网站、帖子和文章的链接,帮助你确定专注点
目录
1. 理解 GAN
2. GAN: 一场革命
1. DCGAN
2. 改进的 DCGAN
3. 条件性 GAN
4. InfoGAN
5. Wasserstein GAN
3. 结语
理解 GAN
如果你熟悉 GAN,可以跳过本节。
如果你正在阅读本文,很有可能已听说 GAN 大有前途。这种夸张说法合理吗?以下是 Facebook 人工智能研究室主任杨立昆(Yann LeCun)对 GAN 的看法:
生成对抗网络(GAN)是过去十年机器学习中最有趣的想法。
我个人认为,GAN 有巨大的潜力,但我们还有很多事情要搞明白。

那么,什么是 GAN?接下来我将要对其做一个简要描述。如果你不熟悉并想了解更多,有很多很棒的网站有很好的解释。我个人推荐 Eric Jang(链接:)和 Brandon Amos(链接:)的博客。
GAN 最初由 Ian Goodfellow 提出,它有两个网络:生成器和鉴别器。两个网络在同一时间进行训练,并在极小极大(minimax)游戏中相互博弈。生成器通过创建逼真的图像来愚弄鉴别器,而鉴别器被训练从而不被生成器所愚弄。

训练概述
首先,生成器生成图像。它通过从简单分布中(例如正态分布)采样向量噪声 Z,然后将该矢量上采样到图像来生成图像。在第一次迭代中,这些图像看起来很嘈杂。然后,鉴别器被给予真、假图像,并学习区分它们。生成器稍后通过反向传播步骤接收鉴别器的「反馈」,在产生图像时变得更好。最后,我们希望假图像的分布尽可能接近真实图像的分布。或者,简单来说,我们希望假图像看起来尽可能貌似真实。
值得一提的是,由于 GAN 中使用的极小极大(minimax)优化,训练有可能相当不稳定。但是,有一些技巧可以用来使得训练更鲁棒。
这就是使得生成的脸部图像逐渐变得更加真实的一个例子:
前两个阶段 GAN 的输出结果。使用的数据集是 CelebA。
代码
如果您对 GAN 的基本实现感兴趣,这里是一些简短代码的链接:
Tensorflow(链接:)
Torch 和 Python(PyTorch):[代码](链接:)[博客文章](链接:)
Torch 和 Lua
这些不是最先进的,但它们很好地抓住了核心思想。如果你正在寻找最佳实现来做自己的东西,请看下一节。
GAN: 一场革命
在这里,我将按照时间顺序大体描述一下过去几年出现的一些有关 GAN 的进展和类型。
深度卷积 GAN(DCGAN)
TL; DR:DCGAN 是 GAN 架构的第一大改进。它们在训练方面更稳定,并产生更高质量的采样。
[文章](链接:https://arxiv.org/abs/1511.06434)
DCGAN 的作者着重于改进初始 GAN 的架构。我认为他们花了很长时间来做深度学习里最令人兴奋的事情:尝试很多参数!好极了!最后,它完全有了回报。除此之外,他们发现:
两个网络都必须进行批量归一化。
采用完全隐藏的连接层不是一个好主意。
避免池化(pooling),简单地跨越你的卷积!
ReLU 激活是你的朋友(几乎总是)。
DCGAN 也是相关的,因为它们已经成为实现和使用 GAN 的主要基准之一。在本文发表之后不久,Theano、Torch、Tensorflow 和 Chainer 中有容易获得的不同实现用于测试你所能想到的任何数据集。因此,如果你遇到奇怪的生成数据集,你完全可以责怪这些人。
在以下情况,你可能想要使用 DCGAN:
你想要比常规 GAN 更好的东西(或者说,总是)。常规 GAN 可以在简单的数据集上工作,但是 DCGAN 相比要好得多。
你正在寻找一个坚实的基准,以便与最新、最先进的 GAN 算法进行比较。
从这一点上,我将描述的所有类型的 GAN 都被假定为具有 DCGAN 架构,除非明确说明。
改进的 DCGAN
TL; DR:一系列改进以前 DCGAN 的技术。比如,这个改进的基准允许生成更好的高分辨率图像。
[文章](链接:https://arxiv.org/abs/1606.03498)
与 GAN 有关的主要问题之一是它们的收敛性。它是不能保证的,而且即使优化了 DCGAN 架构,训练仍然相当不稳定。在这篇文章中,作者提出了对 GAN 训练的不同增强方案。这里是其中的一些:
特征匹配:他们没有使生成器尽可能地欺骗鉴别器,而是提出了一个新的目标函数。该目标要求生成器生成与实际数据的统计信息相匹配的数据。在这种情况下,鉴别器仅用于指出哪些是值得匹配的统计信息。
历史平均:更新参数时,还要考虑其过去值。
单边标签平滑:这一点很简单:只需将你的鉴别器目标输出从 [0 = 假图像,1 = 真图像] 切换到 [0 = 假图像,0.9 =真图像]。是的,这改善了训练。
虚拟批量归一化:通过使用在一个参考批处理中收集的统计信息,避免同一批次的数据依赖性。它在计算上的代价很大,所以仅用于生成器。
所有这些技术都可以使模型更好地生成高分辨率图像,这是 GAN 的弱点之一。作为对比,请参见原始 DCGAN 与改进的 DCGAN 在 128x128 图像上的区别:

这些应该是狗的图像。如你所见,DCGAN 无法表征它们,而使用改进的 DCGAN,你至少可以看到有一些像小狗一样的东西。这也暴露了 GAN 的另一个局限,即生成结构化的内容。
你也许想要使用改进的 DCGAN,如果:
你想要一个改进版本的 DCGAN(我确信你原本不指望:P)以生成更高分辨率的图像。
条件性 GAN(CGAN)
TL; DR:这些是使用额外标签信息的 GAN。这会带来更好质量的图像,并能够在一定程度上控制生成图像的外观。
[来源文章](https://arxiv.org/abs/1411.1784)
条件性 GAN 是 GAN 框架的扩展。这里我们有条件信息 Y 来描述数据的一些方面。例如,如果我们正在处理人脸,则 Y 可以描述头发颜色或性别等属性。然后,将该属性信息插入生成器和鉴别器。
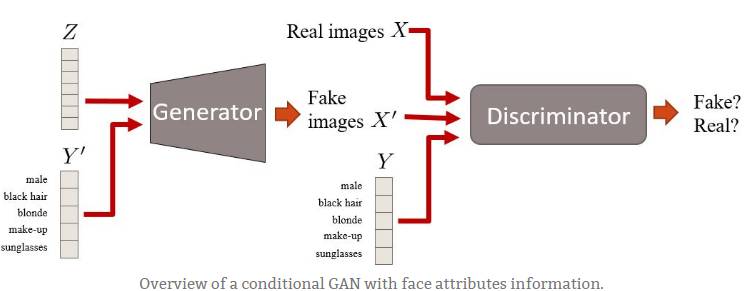
具有面部属性信息的条件性 GAN 概述。
条件性 GAN 有趣的原因有两个:
1. 当你向模型输入更多信息时,GAN 学习利用它,因此能够生成更好的样本。
转载请注明出处。
 相关文章
相关文章 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
