因为示例中的网络是使用 TensorFlow 训练的,我们可以使用 TensorBoard 的可视化计算图监视训练、验证和进行性能测试。在 2017 TensorFlow Dev Summit 上 Dandelion Mane 给出了一些有用的帮助:https://www.youtube.com/watch?v=eBbEDRsCmv4
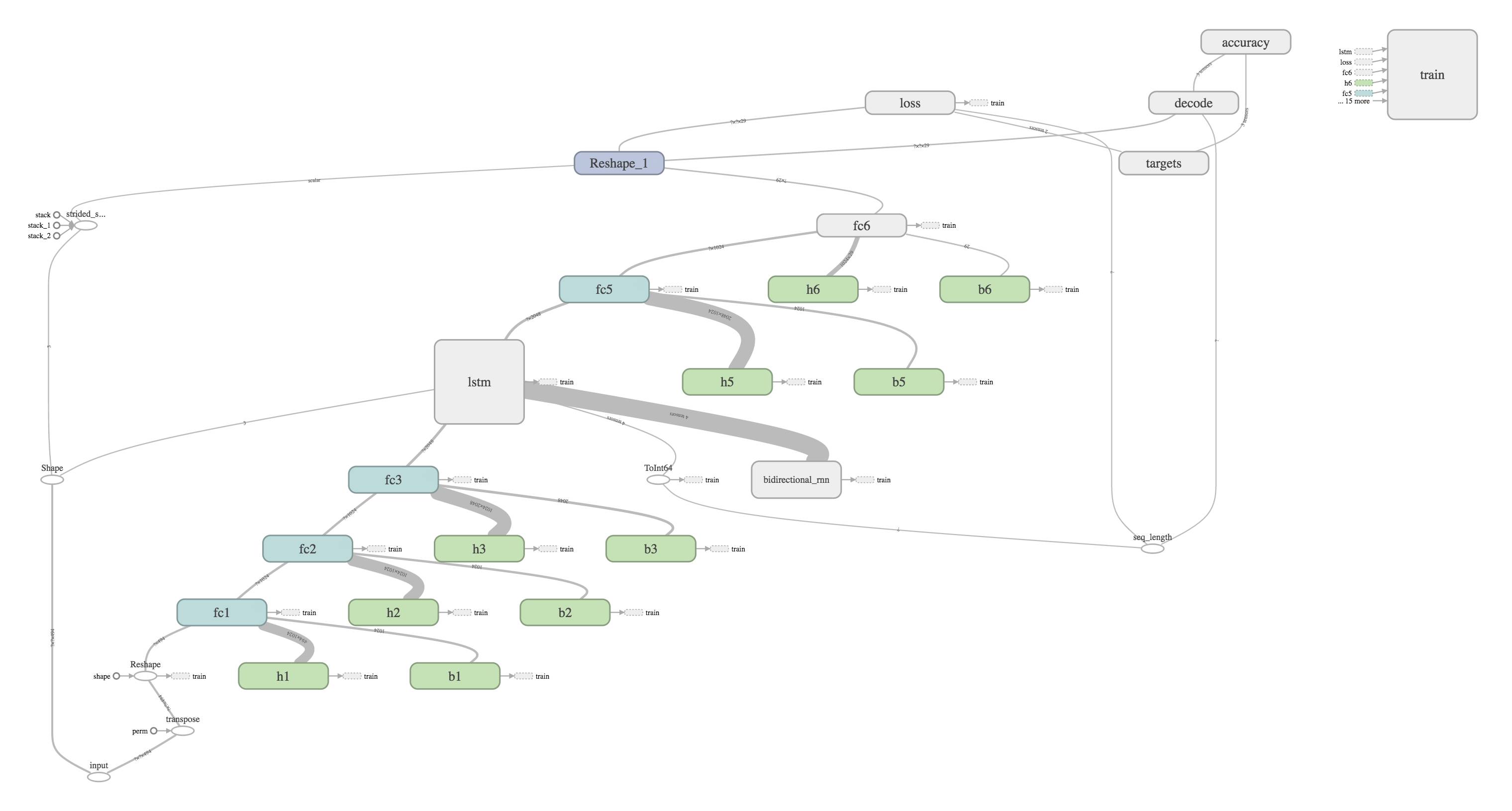
我们利用 tf.name_scope 添加节点和层名称,并将摘要写入文件,其结果是自动生成的、可理解的计算图,正如下面的双向神经网络(BiRNN)所示。数据从左下角到右上角在不同的操作之间传递。为了清楚起见,不同的节点可以用命名空间进行标记和着色。在这个例子中,蓝绿色 fc 框对应于完全连接的层,绿色 b 和 h 框分别对应于偏差和权重。
我们利用 TensorFlow 提供的 tf.train.AdamOptimizer 来控制学习速度。AdamOptimizer 通过使用动量(参数的移动平均数)来改善传统梯度下降,促进超参数动态调整。我们可以通过创建标签错误率的摘要标量来跟踪丢失和错误率:
# Create a placeholder for the summary statistics
with tf.name_scope("accuracy"):
# Compute the edit (Levenshtein) distance of the top path
distance =tf.edit_distance(tf.cast(self.decoded[0], tf.int32), self.targets)
# Compute the label error rate (accuracy)
self.ler =tf.reduce_mean(distance, name='label_error_rate')
self.ler_placeholder =tf.placeholder(dtype=tf.float32, shape=[])
self.train_ler_op =tf.summary.scalar("train_label_error_rate", self.ler_placeholder)
self.dev_ler_op =tf.summary.scalar("validation_label_error_rate", self.ler_placeholder)
self.test_ler_op =tf.summary.scalar("test_label_error_rate", self.ler_placeholder)
如何改进 RNN
现在我们构建了一个简单的 LSTM RNN 网络,下一个问题是:如何继续改进它?幸运的是,在开源社区里,很多大公司都开源了自己的最新语音识别模型。在 2016 年 9 月,微软的论文《The Microsoft 2016 Conversational Speech Recognition System》展示了在 NIST 200 Switchboard 数据中单系统残差网络错误率 6.9% 的新方式。他们在卷积+循环神经网络上使用了几种不同的声学和语言模型。微软的团队和其他研究人员在过去 4 年中做出的主要改进包括:
在基于字符的 RNN 上使用语言模型
使用卷积神经网络(CNN)从音频中获取特征
使用多个 RNN 模型组合
值得注意的是,在过去几十年里传统语音识别模型获得的研究成果,在目前的深度学习语音识别模型中仍然扮演着自己的角色。
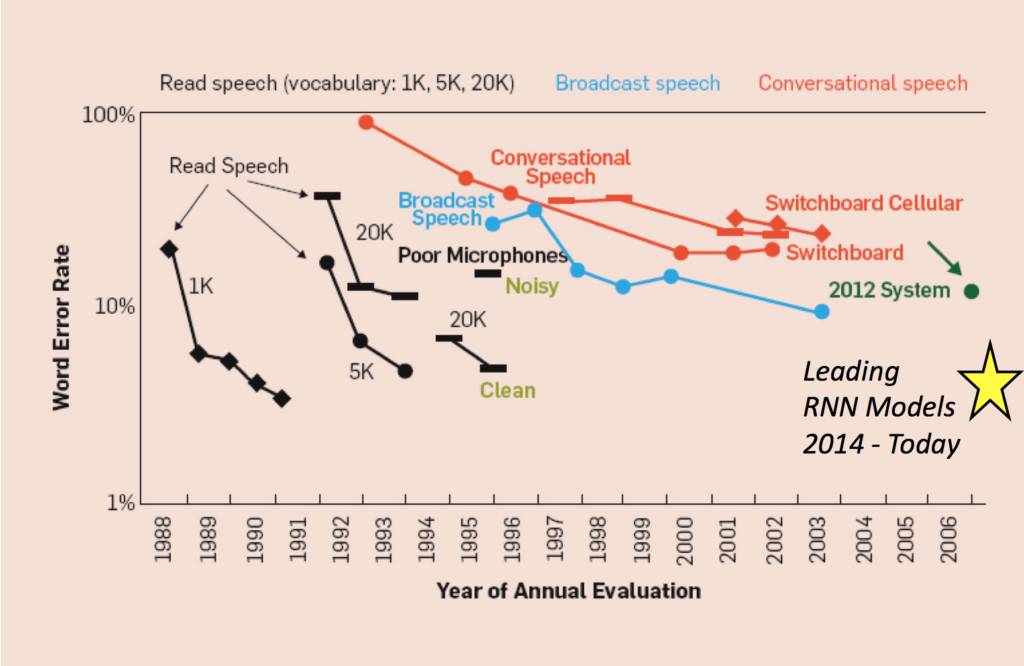
修改自: A Historical Perspective of Speech Recognition, Xuedong Huang, James Baker, Raj Reddy Communications of the ACM, Vol. 57 No. 1, Pages 94-103, 2014
训练你的第一个 RNN 模型
在本教程的 Github 里,作者提供了一些介绍以帮助读者在 TensorFlow 中使用 RNN 和 CTC 损失函数训练端到端语音识别系统。大部分事例数据来自 LibriVox。数据被分别存放于以下文件夹中:
Train: train-clean-100-wav (5 examples)
Test: test-clean-wav (2 examples)
Dev: dev-clean-wav (2 examples)
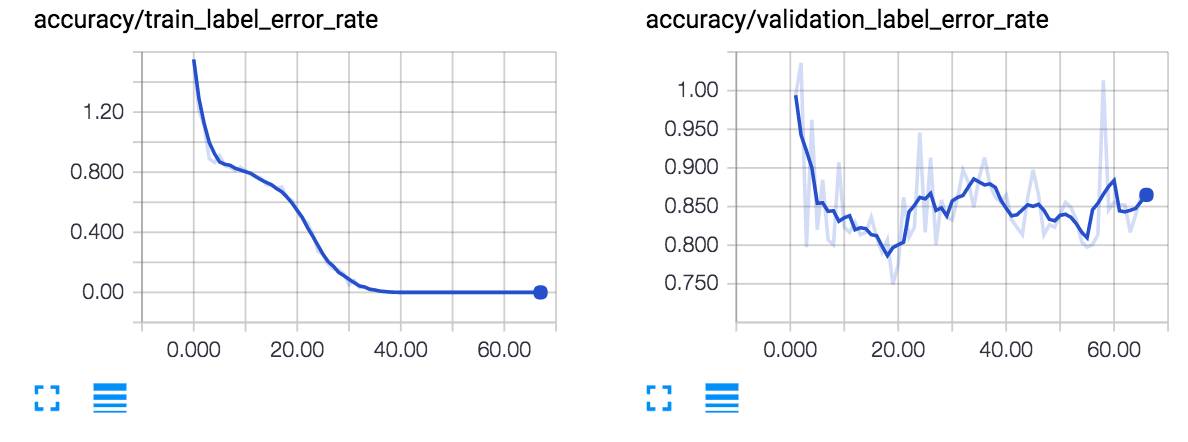
当训练这些示例数据时,你会很快注意到训练数据的词错率(WER)会产生过拟合,而在测试和开发集中词错率则有 85% 左右。词错率不是 100% 的原因在于每个字母有 29 种可能性(a-z、逗号、空格和空白),神经网络很快就能学会:
某些字符(e,a,空格,r,s,t)比其他的更常见
辅音-元音-辅音是英文的构词特征
MFCC 输入声音信号振幅特征的增加只与字母 a-z 有关
使用 Github 中默认设置的训练结果如下:
转载请注明出处。
 相关文章
相关文章 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
