int8指的是用8比特的整型去做神经网络的前向inference。实际测试发现,int8的使用,可以通过数据转化的调整等等操作,把精度的损失降到非常非常的小,打比方说,在做图像分类的时候,精度损失在百分之零点几。对于精算性能的提高,还是很显著的。理论上来说,是四比一的关系。实际上,相对于MP 32的浮点数计算能力,大概是三点几倍。
值得提的一点,Tesla P4实际上是由NVIDIA中国的解决方案工程师针对中国用户的需求,向美国总部提出并设计的产品。你会发现它的功耗比较低,只有50瓦或者70瓦这两种SPEC的SQ,不需要额外供电,能够插在很多没有针对GPU做额外电源设计的服务器里面。
上面主要介绍的是硬件的平台的选择。接下来,主要从整个软件生态上做一个概括性的介绍,大概能了解清楚NVIDIA提供哪些软件库供方便大家使用,很多情况下不需要做重复开发。
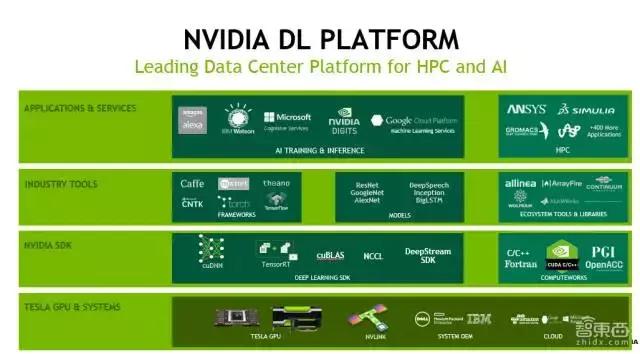
大家看下上面这一页PPT。前面我主要讲的是最下面的Tesla GPU &Systerm,也即最底层的硬件。在这之上,有CUDA Runtime,有基于CUDA的各种各样的算法库,最基本如BlAS做基础的矩阵,相当于运算的库。接下来的话,我会大概的介绍一下主要是三个,一个是CUDNN,一个是TENSORRI,一个是中国团队做的DeepStream。
刚才我又截了几页PPT。其实,每一个软件或库,展开讲可能几个小时都讲不完,所以我这里大概介绍下。
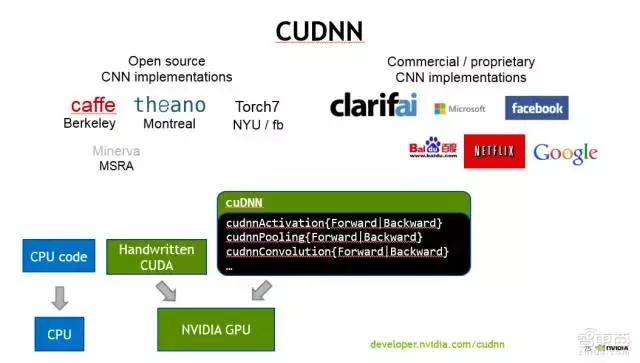
首先讲CUDNN。 CUDNN设计的最主要目标,性能是第一位,其次是灵活性。它主要针对Deep Learning的training工具设计的。换句话说,CUDNN实现了我们在神经网络里面遇到的一些常见layer,或者说是操作。打比方说,一般的卷积convolution、pooling等等defining操作。这些都是按照Deep Learning的开发人员能更方便理解和使用的接口,暴露给大家。
大家在用CUDNN的库的时候,实际上大多数情况下,你都不大需要了解是怎么在GPU上做CUDA代码的开发的,因为这些细节都隐藏在CUDNN后面了。
现在主流的一些可训练工具,像Caffe、Torch7、Theano、MxNet,都提供CUDNN的backend。
作为这些Deep Learning训练工具的研发人员,就可以很方便地用CUDNN 提供的layer的前向与后向的操作,来快速搭建training的库。
当然,我们完全可以基于CUDNN写一个网络的前向计算。我之前也做过类似工作。但是,在大多数情况下,不管是做Deep Learning的训练还是inference,都比较少用CUDNN,或者说CUDNN对大家来讲是透明的。比方说,在编译Caffe的时候,就把CUDNN在Caffe的makefile去给它enabel,然后把CUDNN的库下载下来,编译下Caffe,然后link一下就可以work。实际上是在用CUDNN,但是你没有在代码里面主动调用。
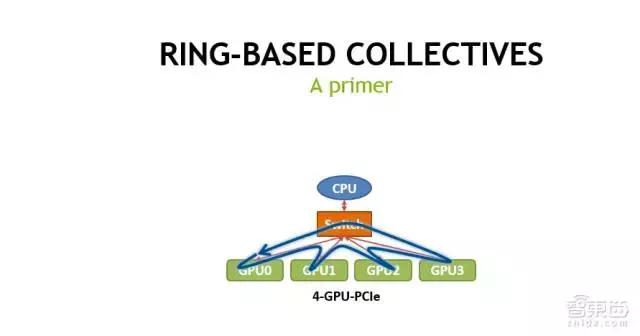
第二页PPT是NVIDIA的NCCL库的作用示意。NCCL主要是为了加速在多GPU环境,同时用多块GPU做training的时候,它做出一个同步,或者说Reduction时候,加速collective的过程。
它的最核心思想是什么呢?在做数据传输的时候,把大块数据切成小块,同时利用系统里面的多条链路,比如现在是PCI-E链路,同时利用PCI-E的上行和下行,尽量去避免不同的数据同时用某一个上行或者下行通道,可能会造成数据的contention,大大降低传输效率。
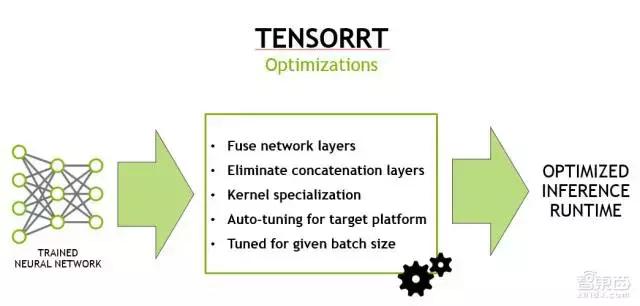
第三页PPT是TENSORRT。TENSORRT的目标很简单,当你训练好了网络,需要部署的时候,能够尽量地加速线上的inference的throughput。TENSORRT跟CUDNN最大的区别在于,CUDNN里面的API都是ProModule,或者说ProLayer,也就是说,在优化卷积的时候,我只知道卷积的参数,然后再做优化;而输入给TENSORRT的信息,是包含整个网络的信息,如layer结构是什么样子,连接关系是怎样的。
所以说,TENSORRT可以做很多CUDNN做不了的优化,这里面列举了一些常用的:
举一个例子,卷积属于比较大的操作。在卷积之后,经常会连接一些小的操作,比如pooling。如果用CUDNN,实际上把计算过程会变成两个API的调用:一个做卷积,一个pooling。这样的话,卷积和pooling之间,首先卷积的结果,要把它存到memory里面去,然后再去做pooling操作,你需要把数据从memory读回来,然后再把最终结果存回去。
Network LayerFusion的一个思想,指的是我既然知道前面是卷积,后面是pooling或者其他操作的话,在有可能的情况下,在前面的这个layer做完之后,我不是把结果立马写回memory里面去,而有一些后面的小操作可以直接做的情况下,我可以先做了之后,再寄存器或者memory。把数据存在那个位置,然后把最终结果算完之后,再一次存回内存里面去,可以显著地提高性能。
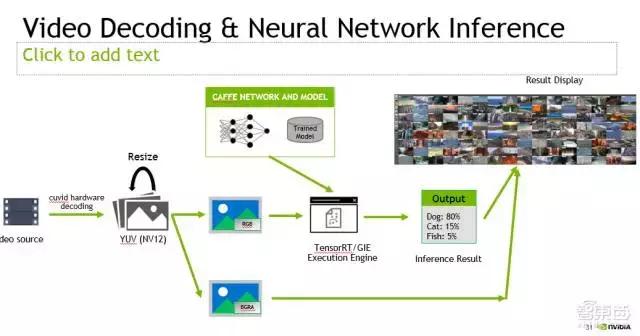
这是前面提到的我们做的DeepStream的SDK。想法也很简单,NVIDIA的GPU上,除了有一般的计算单元,可以用来做神经网络的前向计算,还有做视频编解码的ASIC。
转载请注明出处。
 相关文章
相关文章 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
