接触过NVIDIA加速计算产品的用户,应该都对CUDA这个词不陌生,CUDA从最初发布到今天已经有10年的历史了。CUDA是Compute Unified Device Architecture的缩写,从这个词组本身设计上,可以看出,CUDA的最初开发人员是希望CUDA成为不同平台上的统一计算接口。
NVIDIA的芯片产品主要包括:面向游戏业务的GeForce、面向专业图形图像领域的Quadro、面向企业级计算的Tesla、面向嵌入式计算的Tegra,以及面向虚拟化应用的Grid。
今天CUDA在高性能计算,加速计算领域占据着非常重要的地位,也实现了在NVIDIA各个产品线上统一接口的目标。换句话说,在NIVIDA的GeForce,Quadro,Tesla,Tegra等产品上都可以运行CUDA程序。
GPU当然并不是适合所有的任务,并且在很多情况下,需要跟CPU做很好的配合,由CPU来负责程序中的串行部分。GPU从设计之初是为了加速大量类似操作(比如几百万甚至更多像素的渲染),所以architecture做tradeoff的时候考虑的是获得多个任务总体的高throughput,而不是单个任务的低延迟高相应。GPU拿来做其它任务也必然是类似的,会比较适合大量类似的并发处理,或者说应用的并行度要足够高。
从传统上看,一直到2013年、2014年左后,NVIDIA 的GPU,特别是企业产品Tesla,主要还是应用在传统的高性能计算领域,用户主要是用GPU来加速一些理论物理、分子动力学等等科学计算类的任务。工业界的应用的话,主要集中在石油行业。其他的一些应用,也包括一些金融类应用,比如期权定价等等。那么,2012年Hinton在ImageNet比赛中取得突破性的进展的时候,采用的就是NVIDIA 的GeForce游戏显卡。那么到现在,也就是2017年,机器学习特别是深度学习,已然成为NVIDIA企业级产品应用最大的领域。
从这里我们可以看到,NVIDIA 的GPU产品在最近几年,在深度学习领域取得的成功,是有一定的偶然因素的,也存在一定的必然。说偶然,是因为技术的突破,数据的积累还有计算能力的演进,大概到了这样的一个时间点。必然呢,是因为NVIDIA其实对于Deep Learning的促进,跟在其他领域,特别是科学计算领域对那些应用的促进,并没有本质的区别,都是来源于NVIDIA 在高性能计算领域,对于整个生态环境的持续投入。正是因为有了比较好的软硬件的工具,还有比较完善的生态系统,研究人员才可以很容易的基于GPU去开发所需要的应用。回到Deep Learning,像2012年Hinton他们做的工作,最终引导了这一次比较深刻的技术变革。

我们现在再回到上面已经发过的一页PPT,里面有我们的几个平台或者说方案吧。有大家都用过的游戏显卡,像1080 TitanX这种GeForce、针对深度学习特别开发的Server服务器DGX-1。另外,我们跟很多合作伙伴会推出基于Tesla的服务器,以及我们跟用户或者合作伙伴,像Amazon、阿里云等等,在云端给用户提供有GPU的HPC节点。
这次交流其实很重要的一点,大家在做DL,特别是刚开始做DL训练的时候,选择用什么样的一个方案呢?这里只是我的一些建议:
首先,如果大家在开始或者是初期的时候,如果只有非常少量的服务器,或者说机器。打比方说,我只有四五台 Server,很多人的选择就是先用几块GeForce显卡,稍微先试一试;当需要大规模投入的时候,一般来讲大家都会去选择用企业级产品Tesla。这里面最大的一个原因,在这里就不展开讲,主要是由于硬件设计之初,企业级产品是要保证24小时稳定工作的,不太像消费级产品对容错率要求不是那么高。可以想像一下,假设一块显卡的出错概率,是一个月出错一次,那么你想一下,如果你有一百块,甚至更多的显卡的时候,会是什么样的一个场景。
如果需要大量计算资源的时候,也有两种选择:
1、比如说买一些GPU的Server;
2、选择NVIDIA跟合作伙伴做的Tesla的GPU Server,或者选择DGX-1。
两者之间主要区别是什么呢?DGX-1主要是对扩展性要求比较高的场合。换句话说,当你需要在相对短时间内,对一个比较大的模型进行训练的时候,用DGX-1。
如果你不太有比较大规模训练任务,比如用2块GPU做几个小时就可以完成的,一般用2卡或4卡的机器,都可以满足大家的需求。
那么,到底是自己选择买Server,还是用云服务,也就是HPC GPU节点。主要区别在于你到底想不想在IT这块,也就是硬件的infrastructure上做投入。如果用云服务,硬件维护还有整个环境的管理,都是由云服务商提供的,确实可以省去比较多的麻烦。当然,如果决定自己去维护这个环境的话,可以试图搭建硬件平台。


上面两页是Tesla P100的SPEC。它的具体SPEC,比如峰值是多少等等,我就不详细介绍了。主要说两点,一个是P100用了HBM2高速的memory,它的GPU memory带宽会非常高,第二,GPU之间可以用NV Link进行互联。NV Link单个通路,单向可以做到每秒二十几GB,能够大大地加速GPU之间的数据传输。
NVIDIA推出的DGX-1,是由2个CPU,再加8个P100的GPU所构成的,GPU之间由NV Link进行互联。在做神经网络模型训练的时候,实际上有两个主要步骤:
一是做梯度的计算;
二是做梯度的Reduction;Reduction的时候是需要大量的数据传输。用DGX-1的话,中间利用NV Link,能够显著的缩短Reduction时候内存拷贝所带来的对于scalability的影响。
对于training来讲,选择稍微复杂一点。总结一下,还是要看大家的需求:
如果是少量training需求,特别是一开始尝试的时候,完全可以买一二块消费级显卡先试一试;当变成非常严肃的投资时,当你需要买几十块乃至几百块GPU,还是建议用企业级产品,要么采购GPU服务器,要么用云服务商提供的GPU节点。inference的话,相对简单一些。

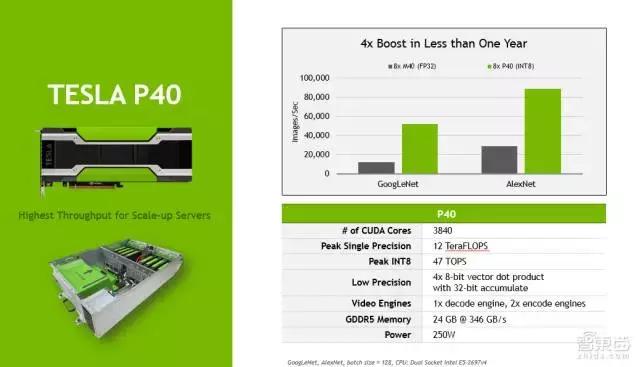
上面是P4和P40两款GPU的SPEC。这里也不详细介绍了。最关键的提一点,就是其中的int8的支持。
转载请注明出处。
 相关文章
相关文章 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
