�������߰������������Ź��ںš����ֹ��С���ID��daiziguizhongren�������߳���ʦ��36봾���Ȩ������
�����ǵ�Сʱ�������˸�������չ������������Ʊ�����²�����ȥ����������ģ��д���ģ�������Ϸ�ģ��н����µģ���̸��˵���ģ��ȵȡ��������Ȥ����һ���ܺ��ҶԻ��Ļ����ˣ������������⣬Ҳ��ش��ҵ����⣬������ѽ��������Ͼ���ң���ĺܿ��ģ������������ѧ�����롣���ǣ��������˸����ң���ʵ��ʱÿ�����������涼�Dz���һ�����ˣ��������п���һ�£���Щ��ɥ����С���������ô�����ˡ�
����
�������ڣ��˹�����ȡ���˷��ٷ�չ�ͽ�������ʱ�ļ���ij����Ѿ���ȫ��ת�ˡ����� AlphaGo ������ʯ��Χ��������������Ŀ�����²�Ӧ����ͼƬ�е�ʯͷ�˻Ʋ�ʿ����ʱ���������ߵ��˺�̨���䵱�����ܵĺ��ģ����ˣ�Ҳ���ǻƲ�ʿ��ֻ�������˻�������ý�顣
����
������������κͿ½�ı�������Ȼû�иı�������״����Ϊ��״̫�Ѹı��ˡ����ǻƲ�ʿ�������ǻƲ�ʿ�����Ļ����ˣ����Ƕ�ô�ڴ������Ļ���������Χ�塣
����
������ô��˵����Щ������Ϊʲô��ô������ AlphaGo������������һ�������ˣ��ܿ����̣��������ӣ���˼��������˵Ц���������档��ʵ����ʱ�����������飬�û���������һ�������Ǻ��������ˡ�
����
�������ˣ����ӽ����ˣ����Թ������ˡ���ñ���ĭ��������������һ�£�AlphaGo ȷʵ�������ģ�Ҳ�������ǣ�Ϊʲô��˵��AlphaGo ͦ���������أ�
��������֪����Χ��������ռ�ܴ���3��19x19�η���״̬��Ҫ����ô��Ŀռ�ȥ�������㷨��һ��һ�����Dz����ܵģ����Ա���Ϊ�������ܵ�һ���ߵ㣬���ʱ��Ҫ�Ż����������Ǹ���һЩ����ռ�Ͳ������ٵ�ģʽʶ������������������������õ�ȴ�Ǵ����ݣ������ʹ������ʵ�ֵġ�˵�� AlphaGo ��������ܺ��㷨���Ͳ��ܲ�˵���ѧϰ��DL����ǿ��ѧϰ��RL���������ؿ�����������MCTS����
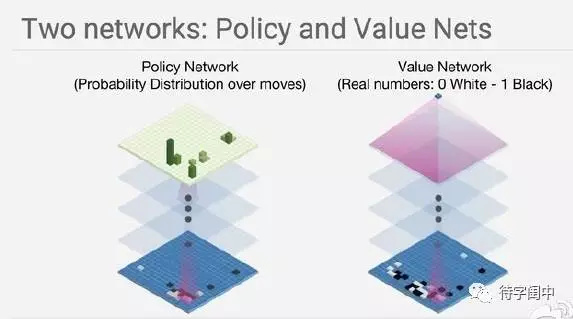
�������ѧϰ����Ҫ����ѧϰ�ͽ�������ģ�����硣һ�����������ڵ�����״̬��Σ�Ҳ����˵����ǰ������״̬����֣�����һ��Ӯ������ֵ�������Ǽ�ֵ���磨Value Network��������������19x19ÿ�����״̬�����ӻ����ӣ������Ӯ������ֵ������˵�����Ҫ����һ����������ѧ�һ��ǻ����㹻������˵�������Ͼ����ںڰ���дһ��������ѧ��ʽ�����ź������ڻ�û�У����ԣ�ֻ���ö�����Ԫ���������Ʊ�ʾ������ĺ�������ô��˵���Dz����е㡰������
�������Ǹ������ڵ�����״̬��������һ�����Ӹ�����߲���������Ӯ�ĸ��ʣ������� AlphaGo �IJ������磨Policy Network����Ҳ����˵����һ��19x19������״̬�������пյĵط����ĸ�����ѵ�ѡ��������Ӯ�ʡ�ͬ����Ҳ������һ�������������������ǵ�ǰ����״̬�������ÿ���մ�����������Ӯ������ֵ�������������û��һ��������ѧ��ʽ�����ԣ����Ҳ�����ڶ�������硣
����
�������ǣ����������ѧϰ����ģ�ͣ���ôѵ���������أ���ʱ�����ò�˵����ݶ��½���SGD����
��������������취��
����
����Ϊ����һ��Ŀ�꺯��������ֵ������һ��ģ��������һ�����η���һ������һ���Ĺ�ʽ���ܵõ����̵Ľ⡣
����
�������ڣ�Χ���������ѧϰҪ���Ŀ�꺯����û��һ������ʽ������ô�죿ֻ�������ڵ���������ݶ��½�������SGD����������ɽ��ÿ������һ�������ǽӽ�ɽ��һ��㣬���߽�����ʯͷ���ӡ��Ͼ������ļ�������ǿ��������ֵ���㣬������ǿ�������ƴ�����㣬ֱ���㵽һ����������Ľ�������֪���˰ɣ�Ϊʲô GPU ���ֶ������������ظ��ļ��㡣��ô˵�����Dz����е㡰��������������һ����ʽ�����ʱ���ʹ�1��ʼ������㣬�����Dz����������������ǣ���ѡ�������ĸ�ѡ�ÿ��ѡ����빫ʽ��һ�¡�
����
������Щ����������������ô������ݣ����������������õ��ģ����Dz�������Ǯѽ����ô�������������ʱ�������Ǿ��ܼ��ٻ����Ѿ�Ԥ���˺ܴ�������ռ䣬���õ�״̬�����õ����ӣ��Ͳ��û�ʱ��ȥ���ˡ���ƽʱ��������ʱ����Ҳ�������ţ��Ͼ����кܶ�״̬û�г��Թ����Ͼ���Щ��ʱ��Ϊ���õ����Ӳ�һ����ã�����ô�죿
����
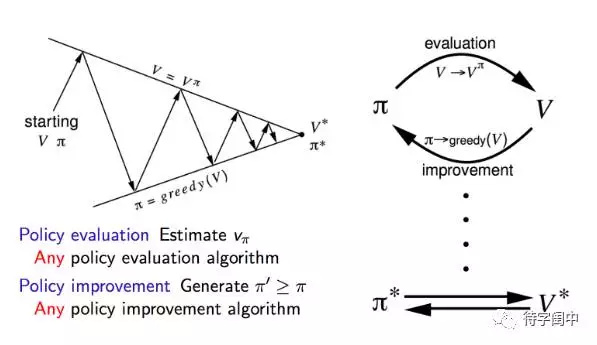
����AlphaGo ���Լ����뷨����������ǿ��ѧϰ��Ҳ����self-play�����������ֻ���������ǰ���Ը���������ռ䣬����δ֪�ռ䣬ͬʱͨ�����ѧϰ������ģ�ͼ�¼���������ǰ������ģ�������Ч������ô���������ʱ��������ϡ������ƽʱ��Ŭ�����ϴ�ͷ��������ģ�ľ�������ʵ�����У���ʱ��ᱻ��Ϊʱ�е㡰������ֻ�����ɡ�
����
������ǿ��ѧϰ���㷨�У�Ҳ��Ҫ�����ĵ������㣬����õ����ŵ�����ֵ��Ҳ���Ǵﵽ���������֡������취��Ч����������
����
����
ת����ע��������
 �������
�������



 ���ʵ���
���ʵ��� ������Ѷ
������Ѷ ��ע����
��ע����
