x = np.array([[[5,10,15,30,25],
[20,30,65,70,90],
[7,80,95,20,30]]
[[3,0,5,0,45],
[12,-2,6,7,90],
[18,-9,95,120,30]]
[[17,13,25,30,15],
[23,36,9,7,80],
[1,-7,-5,22,3]]])
你已经猜到,一个三维张量有三个坐标轴,可以这样看到:
x.ndim
输出为:
3
让我们再看一下上面的邮件列表,现在我们有10个邮件列表,我们将存储2维张量在另一个水桶里,创建一个3维张量,它的形状如下:
(number_of_mailing_lists, number_of_people, number_of_characteristics_per_person)
(10,10000,7)
你也许已经猜到它,但是一个3维张量是一个数字构成的立方体。
我们可以继续堆叠立方体,创建一个越来越大的张量,来编辑不同类型的数据,也就是4维张量,5维张量等等,直到N维张量。N是数学家定义的未知数,它是一直持续到无穷集合里的附加单位。它可以是5,10或者无穷。
实际上,3维张量最好视为一层网格,看起来有点像下图:
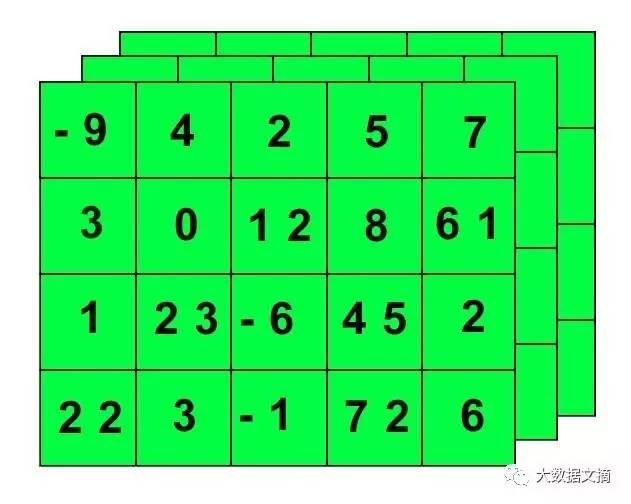
存储在张量数据中的公式
这里有一些存储在各种类型张量的公用数据集类型:
3维=时间序列
4维=图像
5维=视频
几乎所有的这些张量的共同之处是样本量。样本量是集合中元素的数量,它可以是一些图像,一些视频,一些文件或者一些推特。
通常,真实的数据至少是一个数据量。
把形状里不同维数看作字段。我们找到一个字段的最小值来描述数据。
因此,即使4维张量通常存储图像,那是因为样本量占据张量的第4个字段。
例如,一个图像可以用三个字段表示:
(width, height, color_depth) = 3D
但是,在机器学习工作中,我们经常要处理不止一张图片或一篇文档――我们要处理一个集合。我们可能有10,000张郁金香的图片,这意味着,我们将用到4D张量,就像这样:
(sample_size, width, height, color_depth) = 4D
我们来看看一些多维张量存储模型的例子:
时间序列数据
用3D张量来模拟时间序列会非常有效!
医学扫描――我们可以将脑电波(EEG)信号编码成3D张量,因为它可以由这三个参数来描述:
(time, frequency, channel)
这种转化看起来就像这样:
如果我们有多个病人的脑电波扫描图,那就形成了一个4D张量:
(sample_size, time, frequency, channel)
Stock Prices
在交易中,股票每分钟有最高、最低和最终价格。如下图的蜡烛图所示:
纽交所开市时间从早上9:30到下午4:00,即6.5个小时,总共有6.5 x 60 = 390分钟。如此,我们可以将每分钟内最高、最低和最终的股价存入一个2D张量(390,3)。如果我们追踪一周(五天)的交易,我们将得到这么一个3D张量:
(week_of_data, minutes, high_low_price)
即:(5,390,3)
同理,如果我们观测10只不同的股票,观测一周,我们将得到一个4D张量
(10,5,390,3)
假设我们在观测一个由25只股票组成的共同基金,其中的每只股票由我们的4D张量来表示。那么,这个共同基金可以有一个5D张量来表示:
(25,10,5,390,3)
文本数据
我们也可以用3D张量来存储文本数据,我们来看看推特的例子。
首先,推特有140个字的限制。其次,推特使用UTF-8编码标准,这种编码标准能表示百万种字符,但实际上我们只对前128个字符感兴趣,因为他们与ASCII码相同。所以,一篇推特文可以包装成一个2D向量:
(140,128)
如果我们下载了一百万篇川普哥的推文(印象中他一周就能推这么多),我们就会用3D张量来存:
(number_of_tweets_captured, tweet, character)
这意味着,我们的川普推文集合看起来会是这样:
(1000000,140,128)
图片
4D张量很适合用来存诸如JPEG这样的图片文件。之前我们提到过,一张图片有三个参数:高度、宽度和颜色深度。一张图片是3D张量,一个图片集则是4D,第四维是样本大小。
著名的MNIST数据集是一个手写的数字序列,作为一个图像识别问题,曾在几十年间困扰许多数据科学家。现在,计算机能以99%或更高的准确率解决这个问题。即便如此,这个数据集仍可以当做一个优秀的校验基准,用来测试新的机器学习算法应用,或是用来自己做实验。

Keras 甚至能用以下语句帮助我们自动导入MNIST数据集:
from keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
这个数据集被分成两个部分:训练集和测试集。数据集中的每张图片都有一个标签。这个标签写有正确的读数,例如3,7或是9,这些标签都是通过人工判断并填写的。
训练集是用来训练神经网络学习算法,测试集则用来校验这个学习算法。
MNIST图片是黑白的,这意味着它们可以用2D张量来编码,但我们习惯于将所有的图片用3D张量来编码,多出来的第三个维度代表了图片的颜色深度。
MNIST数据集有60,000张图片,它们都是28 x 28像素,它们的颜色深度为1,即只有灰度。
TensorFlow这样存储图片数据:
(sample_size, height, width, color_depth).
于是我们可以认为,MNIST数据集的4D张量是这样的:
(60000,28,28,1)
彩色图片
彩色图片有不同的颜色深度,这取决于它们的色彩(注:跟分辨率没有关系)编码。一张典型的JPG图片使用RGB编码,于是它的颜色深度为3,分别代表红、绿、蓝。
这是一张我美丽无边的猫咪(Dove)的照片,750 x750像素,这意味着我们能用一个3D张量来表示它:
(750,750,3)

My beautiful cat Dove (750 x 750 pixels)
转载请注明出处。
 相关文章
相关文章 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
