ÐÂÖĮÔŠąāŌë
ĀīÔīĢšThe Morning Paper
ŨũÕßĢšAdrian Colyer
ąāŌëĢšÎÅ·Æ
ĄĄĄĄĄūÐÂÖĮÔŠĩžķÁĄŋICLR-17 ŨîžŅÂÛÎÄĄķĀí―âÉîķČŅ§Ï°ÐčŌŠÖØÐÂËžŋž·šŧŊĄ·ŌýÆðđýđã·šÕųŌéĢŽĩŦÅŠĮåÉîķČÉņūÍøÂį·šŧŊąūÖĘÎÞŌÉĘĮÖØŌŠĩÄÎĘĖâĄĢÐÂÖĮÔŠÔÚČĄĩÃąūÎÄŨũÕß Adrian Colyer ĘÚČĻšóĢŽąāŌëÁËËûÔÄķÁļÃÂÛÎÄĩÄļÐÏëĢŽŌēŧķÓÁôÏÂÄãĩÄŋī·ĻĄĢ
ĄĄĄĄĄūąāÕß°īĢšÓÐđØĄķĀí―âÉîķČŅ§Ï°ÐčŌŠÖØÐÂËžŋž·šŧŊĄ·ÂÛÎÄ―éÉÜžûÎÄÄĐĢŧŧŌÉŦžÓīÖŨÖĖåīúąíŌýŨÔÂÛÎÄĢŧšėÉŦžÓīÖĘĮÐÂÖĮÔŠąāžžÓĩÄĄŋ
ĄĄĄĄĢĻÎÄĢŊAdrion ColyerĢĐÕâÆŠÂÛÎÄÓКÜķāÓÅĩãĢš―áđûžōĩĨŌŨķŪĢŽŧđÓÐÐĐģöšõŌâÁÏĢŽŧáČÃÄãÔÚ―ÓÏÂĀīšÜģĪŌŧķÎĘąžäËžŋžÕâŌŧĮÐŋÉÄÜŌâÎķŨÅĘēÃīĢĄ
ĄĄĄĄŨũÕßŌŧŋŠĘžĖáģöĩÄÎĘĖâĘĮĢš
ĄĄĄĄĄ°·šŧŊšÃĩÄÉņūÍøÂįšÍ·šŧŊēŧšÃĩÄÉņūÍøÂįÓÐĘēÃīĮøąðĢŋķÔÕâŌŧÎĘĖâŨöģöÂúŌâĩÄŧØīðĢŽēŧ―öÓÐÖúÓÚļüšÃĩØĀí―âÉņūÍøÂįĢŽŧđŋÉÄÜīøĀīļüÕýČ·ĢĻprincipledĢĐŋÉŋŋĩÄÄĢÐÍžÜđđÉčžÆĄĢĄą
ĄĄĄĄŨũÕßËĩĄ°·šŧŊšÃĄąĩÄŌâËžĢŽūÍĘĮžōĩĨÖļĄ°ĘĮĘēÃīÔŌōĩžÖÂÔÚŅĩÁ·ĘýūÝÉÏąíÏ֚ܚÃĩÄÍøÂįĢŽÔÚĢĻÃŧÓÐ―ÓīĨđýĩÄĢĐēâĘÔĘýūÝÉÏąíÏÖŌēšÜšÃĢŋĄąĢĻÓëĮĻŌÆŅ§Ï°ēŧÍŽĢŽĮĻŌÆŅ§Ï°ŨöĩÄĘĮ―ŦŌŧļöŅĩÁ·šÃĩÄÍøÂįÓÃÓÚÁíÍâŌŧļöÏāđØĩŦēŧÍŽĩÄÎĘĖâĢĐĄĢ
ĄĄĄĄŧĻĩãĘąžäÏëŌŧÏÂĢŽÕâļöÎĘĖâŧųąūŋÉŌÔđé―áΊĢšĄ°ÎŠĘēÃīÉņūÍøÂįЧđûÕâÃīšÃĢŋĄąÖÁÓÚ·šŧŊĢŽŌŧļöĘĮÖŧžĮŨĄēŋ·ÖŅĩÁ·ĘýūÝķøšó―ŦÆäÖØļīģöĀīĢŽŌŧļöÔōĘĮÕæÕýķÔŋÉŌÔÓÃĀī―øÐÐÔĪēâĩÄĘýūÝžŊēúÉúŌŧÐĐÓÐŌâŌåĩÄ·ĒÏÖĢĻintuitionĢĐĢŽÕâÁ―ÕßĩÄĮøąðūÍĘĮ·šŧŊĄĢ
ĄĄĄĄËųŌÔĢŽŌŠĘĮÎŌÃĮķÔĄ°ÎŠĘēÃīÉņūÍøÂįąíÏÖĢĻ·šŧŊĢĐÕâÃīšÃĢŋĄąļøģöĩÄŧØīðĘĮĢšĄ°ÎŌÃĮÕæĩÄēŧÖŠĩĀĢĄĄąĄŠĄŠĘÂĮéūÍÓÐÐĐÞÏÞÎÁËĄĢ
ĄĄĄĄēŧŋÉËžŌéĩÄËæŧúąęĮĐ°ļĀý
ĄĄĄĄđĘĘÂīÓŌŧļöĘėÏĪĩÄĩØ·―ŋŠĘžĄŠĄŠCIFAR 10ĢĻšŽÓÐ 5 Íō·ųŅĩÁ·ÍžÏņĢŽ·ÖΊ 10 ļöĀāĢŽ1 Íō·ųŅéÖĪÍžÏņĢĐšÍ ILSVRCĢĻImageNetĢĐ2012ĢĻ1,281,167 ŅĩÁ·ĘýūÝĢŽ5 Íō·ųŅéÖĪÍžÏņĢŽ1000 ļöĀāąðĢĐĘýūÝžŊšÍ Inception ÍøÂįžÜđđĩÄąäĖåĄĢ
ĄĄĄĄĘđÓÃŅĩÁ·ĘýūÝŅĩÁ·ÍøÂįĢŽČŧšóÔÚĄ°ŅĩÁ·ĘýūÝžŊĄąÉÏīíÎóΊ 0ĢŽÕâÃŧĘēÃīšÃÆæđÖĩÄĄĢÕâģä·ÖËĩÃũÁËđýÄâšÏĄŠĄŠžĮŨĄŅĩÁ·ŅųąūĢŽķøēŧĘĮŅ§Ï°ķÔĖØÕũ―øÐÐÕæÕýĩÄÔĪēâĄĢÎŌÃĮŋÉŌÔĘđÓÃÕýÔōŧŊžžĘõÓĶķÔđýÄâšÏĢŽÉčžÆģö·šŧŊÐÔÄÜļüšÃĩÄÍøÂįĄĢÕâļöŧ°ĖâÎŌÃĮÉÔšóÔŲËĩĄĢ
ĄĄĄĄČÔČŧĘđÓÃÏāÍŽĩÄŅĩÁ·ĘýūÝĢŽĩŦÕâīÎ―ŦąęĮĐīōÂŌĢĻĘđąęĮĐšÍÍžÏņÖÐĩÄÄÚČÝēŧÔŲūßÓÐÕæÕýĩÄķÔÓĶđØÏĩĢĐĄĢĘđÓÃÕâÐĐąęĮĐËæŧúĩÄĘýūÝŅĩÁ·ÍøÂįĢŽŧáĩÃĩ―ĘēÃīĢŋŅĩÁ·īíÎóŧđĘĮ 0ĢĄ
ĄĄĄĄĄ°ÔÚÕâÖÖĮéŋöÏÂĢŽĘĩĀýšÍ·ÖĀāąęĮĐÖŪžäēŧÔŲÓÐČΚÎđØÏĩĄĢŌōīËĢŽŅ§Ï°ĘĮēŧŋÉÄÜ·ĒÉúĩÄĄĢÖąūõļæËßÎŌÃĮĢŽÕâÖÖēŧŋÉÄÜŧáÔÚŅĩÁ·đýģĖÖКÜĮåģþĩØąíÏÖģöĀīĢŽąČČįŅĩÁ·ēŧĘÕÁēĢŽŧōÕßĘÕÁēËŲķČīó·ųžõÂýĄĢČÃÎŌÃĮļÐĩ―ŌâÍâĩÄĘĮĢŽÓÐķāļöąęŨžžÜđđĩÄŅĩÁ·đýģĖĩÄšÃÐĐĘôÐÔĢŽÔÚšÜīóģĖķČÉÏķžÃŧÓÐĘÜÕâÖÖąęĮĐŨŠŧŧĩÄÓ°ÏėĄĢĄą
ĄĄĄĄÕýČįŨũÕßËųŅÔĢŽĄ°ÉîķČÉņūÍøÂįšÜČÝŌŨÄâšÏËæŧúąęĮĐĄąĄĢīÓĩÚŌŧļöĘĩŅéÖÐŋÉŌÔŋīģöŌÔÏ 3 ļöđØžüĩãĢš
ÉņūÍøÂįĩÄÓÐЧČÝÁŋŨãŌÔžĮŨĄÕûļöĘýūÝžŊĢŧ
ķÔąęĮĐËæŧúĩÄĘýūÝ―øÐÐÓÅŧŊšÜČÝŌŨĄĢĘÂĘĩÉÏĢŽÓëąęĮĐÕýČ·ĩÄŅĩÁ·đýģĖÏāąČĢŽËæŧúąęĮĐĩÄŅĩÁ·ĘąžäŌēÖŧÔöžÓŌŧļöÐĄĩÄģĢĘýŌōŨÓĢŧ
―ŦąęĮĐīōÂŌ―ö―öĘĮŨöÁËŌŧļöĘýūÝŨŠŧŧĢŽÆäËûËųÓÐđØÓÚŅ§Ï°ÎĘĖâĩÄĘôÐÔķžÃŧÓÐļÄąäĄĢ
ĄĄĄĄēŧđýĢŽČįđûÄã°ŅĘđÓÃËæŧúąęĮĐŅĩÁ·ĩÄÍøÂįÔÚēâĘÔĘýūÝžŊÉÏÅÜŌŧąéĢŽ―áđûĩąČŧēŧŧášÃĢŽŌōΊÍøÂįĘĩžĘÉÏēĒÃŧÓÐīÓĘýūÝžŊÖÐŅ§ĩ―ĘēÃīĄĢÓÃŨĻŌĩŌŧĩãĩÄŧ°ËĩĢŽūÍĘĮÍøÂįĩÄ·šŧŊÎóēîšÜļߥĢ
ĄĄĄĄŨÛÉÏŋÉĩÃĢš
ĄĄĄĄĄ°ĄĄÍĻđý―ŦąęĮĐËæŧúŧŊĢŽÎŌÃĮŋÉŌÔĮŋÖÆÄĢÐÍēŧĘÜļÄąäĄĒąĢģÖÍŽŅųīóÐĄĄĒģŽēÎĘýŧōÓÅŧŊÆũĩÄĮéŋöÏÂĢŽīó·ųĖáÉýÍøÂįĩÄ·šŧŊÎóēîĄĢÎŌÃĮÔÚ CIFAR 10 šÍ ImageNet ·ÖĀāŧųŨžÉÏŅĩÁ·Á˚ÞļÖÖēŧÍŽąęŨžžÜđđĢŽÖĪĘĩÁËÕâŌŧĩãĄĢĄą
ĄĄĄĄŧŧūäŧ°ËĩĢšÄĢÐÍąūÉíĄĒÄĢÐÍīóÐĄĄĒģŽēÎĘýšÍÓÅŧŊÆũķžēŧÄÜ―âĘÍĩąĮ°ŨîšÃĩÄÉņūÍøÂįĩÄ·šŧŊÐÔÄÜĄĢŌōΊÔÚÆäËûĖõžþķžēŧąäĩÄĮéŋöÏÂĢŽÎĻķĀ·šŧŊÎóēîēúÉúīó·ųąäķŊĢŽÖŧÄÜĩÃģöÕâŌŧļöīð°ļĄĢ
ĄĄĄĄļüžÓēŧŋÉËžŌéĩÄËæŧúÍžÏņ°ļĀý
ĄĄĄĄēŧ―ö―öīōÂŌąęĮĐĢŽ°ŅÍžÏņąūÉíŌēīōÂŌĢŽŧá·ĒÉúĘēÃīÄØĢŋŧōÕßĢŽļÉīāÓÃËæŧúÔëÉųīúĖæÕæĘĩÍžÏņĢŋĢŋ
ĄĄĄĄÂÛÎÄļøģöĩÄÍžÖÐĢŽ―ŦÕâŌŧĘĩŅéąęžĮΊĄ°ļßËđĄąĘĩŅéĢŽŌōΊŨũÕßΊÃŋ·ųÍžÏņÉúģÉËæŧúÏņËØĩÄ·―·ĻĢŽĘĮĘđÓÃÁËÆĨÅäÔʞ͞ÏņĘýūÝžŊūųÖĩšÍ·―ēîĩÄļßËđ·ÖēžĄĢ
ĄĄĄĄ―áđûĢŽÍøÂįĩÄŅĩÁ·īíÎóŌĀČŧΊ 0ĢŽķøĮŌËųÓÃĩÄĘąžäŧđąČËæŧúąęĮĐļüÉŲĢĄķÔīËĢŽŌŧÖÖžŲËĩĘĮĢŽËæŧúąęĮĐÍžÏņķžĘôÓÚŌŧļöĀāąðĢŽĩŦÓÉÓÚ―ŧŧŧÁËąęĮĐĢŽēŧĩÃēŧŨũΊēŧÍŽĀāąðĩÄÍžÏņĘýūÝ―øÐÐŅ§Ï°ĢŽķøËæŧúÏņËØÍžÏņąËīËÖŪžäļü·ÖÉĒĄĢ
ĄĄĄĄŨũÕßÍÅķÓŨöÁËķāīÎĘĩŅéĢŽ―ŦŌŧÏĩÁÐēŧÍŽģĖķČšÍĀāÐÍĩÄËæŧúÐÔžÓČëĘýūÝžŊĢš
ÕæĘĩąęĮĐĢĻÔĘžĘýūÝžŊĢŽÃŧŨöÐÞļÄĢĐ
ēŋ·ÖËðŧĩĩÄąęĮĐĢĻ―ŦÆäÖÐŌŧēŋ·ÖąęĮĐīōÂŌÁËĢĐ
ËæŧúąęĮĐĢĻ°ŅËųÓÐąęĮĐķžīōÂŌĢĐ
shuffle ÏņËØĢĻŅĄÔņŌŧļöÏņËØÅÅÁÐĢŽČŧšó―ŦÆäÍģŌŧĢÛuniformlyĢÝÓÃÓÚËųÓÐÍžÏņĢĐ
ËæŧúÏņËØĢĻķÔÃŋ·ųÍžÏņĩĨķĀŨöŌŧļöēŧÍŽĩÄËæŧúÅÅÁÐĢĐ
ļßËđ·―·ĻĢĻČįÉÏÎÄËųĘöĢŽļøÃŋ·ųÍžÏņÔöžÓËæŧúÉúģÉĩÄÏņËØĢĐ
ĄĄĄĄ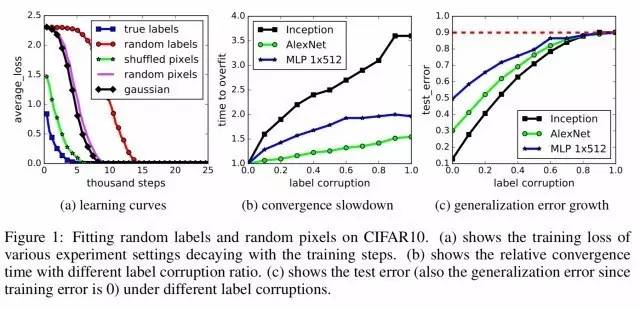
ĄĄĄĄŌŧ·ÏÂĀīĢŽÍøÂįČÔČŧÄÜđŧÍęÃĀĩØÄâšÏŅĩÁ·ĘýūÝĄĢ
ĄĄĄĄĄ°īËÍâĢŽÎŌÃĮ―øŌŧē―ļÄąäÁËËæŧúÐÔĩÄĘýÁŋĢŽÔÚÎÞÔëÉųšÍÍęČŦÔëÉųĩÄĮéŋöÏÂÆ―ŧŽĩØēåČëĘýūÝžŊĄĢÕâŅųŌŧĀīĢŽąęĮĐŧđĘĮąĢÓÐÄģÖÖģĖķČĩÄÐÅšÅĢŽīÓķøŧáÔėģÉŌŧÏĩÁОä―ÓĩÄŅ§Ï°ÎĘĖâĄĢËæŨÅÔëÉųËŪÆ―ĩÄĖáļßĢŽÎŌÃĮđÛēėĩ―·šŧŊÎóēîģĘÏÖģöÎČķĻĩÄķņŧŊĄĢÕâąíÃũÉņūÍøÂįÄÜđŧĀí―âĘýūÝÖÐĩÄĘĢÓāÐÅšÅĢŽÍŽĘąÓÃąĐÁĶžÆËãĘĘÓĶÔëÉųēŋ·ÖĄĢĄą
ĄĄĄĄķÔÎŌķøŅÔĢŽŨîšóŌŧūäŧ°ĘĮđØžüĄĢÎŌÃĮÔÚÉčžÆÄĢÐÍžÜđđĩÄđýģĖÖÐĢŽÄģÐĐūöķĻÏÔČŧŧáÓ°ÏėÄĢÐÍĩÄ·šŧŊÄÜÁĶĄĢĩąĘýūÝÖÐÃŧÓÐÆäËûÕæĘĩÐÅšÅĘąĢŽĘĀ―įÉÏ·šŧŊÐÔÄÜŨîšÃĩÄÍøÂįŌēēŧĩÃēŧÍËŧØČĨËßÖîÓÚžĮŌäĄĢ
ĄĄĄĄËųŌÔĢŽŌēÐíÎŌÃĮÐčŌŠŌŧÖÖ·―·ĻĢŽ―ŦĘýūÝžŊÕæÕýĩÄ·šŧŊĮąÁĶĘáĀíĮåģþĢŽÍŽĘąÅŠÃũ°ŨļøķĻÄĢÐÍžÜđđŧņČĄÕâÖÖĮąÁĶЧđûČįšÎĄĢķÔīËĢŽŌŧļöžōĩĨĩÄ·―·ĻĘĮÔÚÍŽŌŧļöĘýūÝžŊÉÏŅĩÁ·ēŧÍŽĩÄžÜđđĢĄĄŠĄŠĩąČŧĢŽÎŌÃĮŌŧÖąķžÔÚÕâÃīŨöĄĢĩŦÕâķÔÓÚÎŌÃĮģõÖÔĄŠĄŠĀí―âΊĘēÃīŌŧÐĐÄĢÐÍąČÆäËûÄĢÐÍ·šŧŊĩÃļüšÃĄŠĄŠČÔČŧÃŧĘēÃīÓÃīĶĄĢ
ĄĄĄĄÕýÔōŧŊ·―·ĻūČģĄĢŋ
ĄĄĄĄÄĢÐÍžÜđđąūÉíÏÔČŧēŧŨãŌÔŨũΊŌŧļöšÏļņĩÄÕýÔōŧŊšŊĘýĢĻēŧÄÜ·ĀÖđđýÄâšÏ/žĮŌäĢĐĄĢĩŦĘĮĢŽģĢÓÃĩÄÕýÔōŧŊžžĘõÄØĢŋ
ĄĄĄĄĄ°ÎŌÃĮąíÃũĢŽÏÔĘ―ÕýÔōŧŊ·―·ĻĢŽČįČĻÖØËĨžõĄĒdropout šÍĘýūÝÔöĮŋĢŽķžēŧÄÜģä·Ö―âĘÍÉņūÍøÂįĩÄ·šŧŊÎóēîĢšÏÔĘ―ÕýÔōŧŊČ·ĘĩŋÉŌÔĖáļß·šŧŊÐÔÄÜĢŽĩŦÆäąūÉížČÃŧąØŌŠŌēēŧŨãŌÔŋØÖÆ·šŧŊÎóēîĄĢĄą
ĄĄĄĄ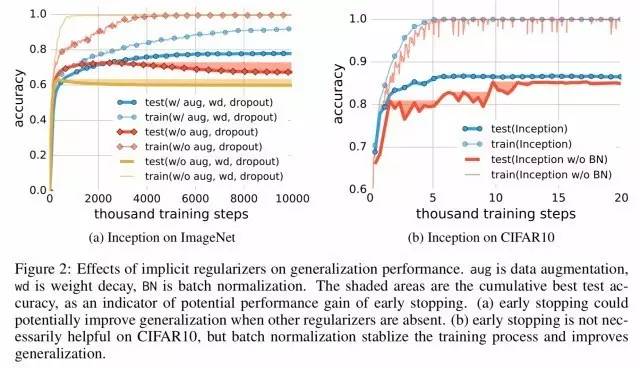
ŨŠÔØĮëŨĒÃũģöīĶĄĢ
 ÏāđØÎÄÕÂ
ÏāđØÎÄÕÂ
 ūŦēĘĩžķÁ
ūŦēĘĩžķÁ ČČÃÅŨĘŅķ
ČČÃÅŨĘŅķ đØŨĒÎŌÃĮ
đØŨĒÎŌÃĮ
