R 资源:http://mxnet.io/
2.4 支持向量机
支持向量机(SVM)可以使用一个称之为核函数的技巧扩展到非线性分类问题,而该算法本质上就是计算两个称之为支持向量的观测数据之间的距离。SVM 算法寻找的决策边界即最大化其与样本间隔的边界,因此支持向量机又称为大间距分类器。
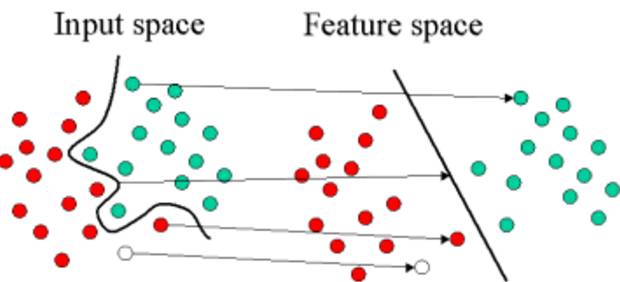
支持向量机中的核函数采用非线性变换,将非线性问题变换为线性问题
例如,SVM 使用线性核函数就能得到类似于 logistic 回归的结果,只不过支持向量机因为最大化了间隔而更具鲁棒性。因此,在实践中,SVM 最大的优点就是可以使用非线性核函数对非线性决策边界建模。
优点:SVM 能对非线性决策边界建模,并且有许多可选的核函数形式。SVM 同样面对过拟合有相当大的鲁棒性,这一点在高维空间中尤其突出。
缺点:然而,SVM 是内存密集型算法,由于选择正确的核函数是很重要的,所以其很难调参,也不能扩展到较大的数据集中。目前在工业界中,随机森林通常优于支持向量机算法。
Python 实现:http://scikit-learn.org/stable/modules/svm.html#classification
R 实现:https://cran.r-project.org/web/packages/kernlab/index.html
2.5 朴素贝叶斯
朴素贝叶斯(NB)是一种基于贝叶斯定理和特征条件独立假设的分类方法。本质上朴素贝叶斯模型就是一个概率表,其通过训练数据更新这张表中的概率。为了预测一个新的观察值,朴素贝叶斯算法就是根据样本的特征值在概率表中寻找最大概率的那个类别。
之所以称之为「朴素」,是因为该算法的核心就是特征条件独立性假设(每一个特征之间相互独立),而这一假设在现实世界中基本是不现实的。
优点:即使条件独立性假设很难成立,但朴素贝叶斯算法在实践中表现出乎意料地好。该算法很容易实现并能随数据集的更新而扩展。
缺点:因为朴素贝叶斯算法太简单了,所以其也经常被以上列出的分类算法所替代。
Python 实现:http://scikit-learn.org/stable/modules/naive_bayes.html
R 实现:https://cran.r-project.org/web/packages/naivebayes/index.html
3、聚类
聚类是一种无监督学习任务,该算法基于数据的内部结构寻找观察样本的自然族群(即集群)。使用案例包括细分客户、新闻聚类、文章推荐等。
因为聚类是一种无监督学习(即数据没有标注),并且通常使用数据可视化评价结果。如果存在「正确的回答」(即在训练集中存在预标注的集群),那么分类算法可能更加合适。
3.1 K 均值聚类
K 均值聚类是一种通用目的的算法,聚类的度量基于样本点之间的几何距离(即在坐标平面中的距离)。集群是围绕在聚类中心的族群,而集群呈现出类球状并具有相似的大小。聚类算法是我们推荐给初学者的算法,因为该算法不仅十分简单,而且还足够灵活以面对大多数问题都能给出合理的结果。
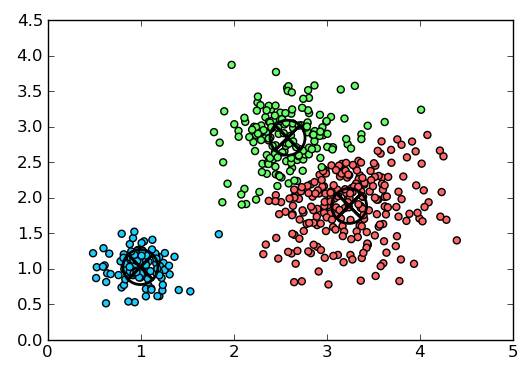
优点:K 均值聚类是最流行的聚类算法,因为该算法足够快速、简单,并且如果你的预处理数据和特征工程十分有效,那么该聚类算法将拥有令人惊叹的灵活性。
缺点:该算法需要指定集群的数量,而 K 值的选择通常都不是那么容易确定的。另外,如果训练数据中的真实集群并不是类球状的,那么 K 均值聚类会得出一些比较差的集群。
Python 实现:http://scikit-learn.org/stable/modules/clustering.html#k-means
R 实现:https://stat.ethz.ch/R-manual/R-devel/library/stats/html/kmeans.html
3.2 Affinity Propagation 聚类
AP 聚类算法是一种相对较新的聚类算法,该聚类算法基于两个样本点之间的图形距离(graph distances)确定集群。采用该聚类方法的集群拥有更小和不相等的大小。
优点:该算法不需要指出明确的集群数量(但是需要指定「sample preference」和「damping」等超参数)。
缺点:AP 聚类算法主要的缺点就是训练速度比较慢,并需要大量内存,因此也就很难扩展到大数据集中。另外,该算法同样假定潜在的集群是类球状的。
Python 实现:http://scikit-learn.org/stable/modules/clustering.html#affinity-propagation
R 实现:https://cran.r-project.org/web/packages/apcluster/index.html
3.3 层次聚类(Hierarchical / Agglomerative)
层次聚类是一系列基于以下概念的聚类算法:
最开始由一个数据点作为一个集群
对于每个集群,基于相同的标准合并集群
重复这一过程直到只留下一个集群,因此就得到了集群的层次结构。
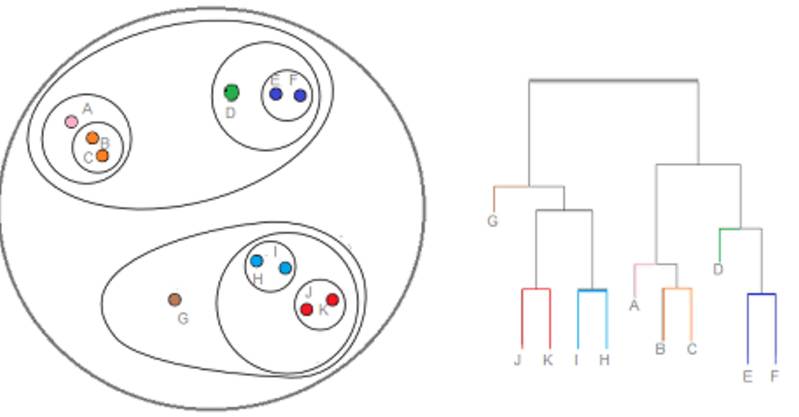
优点:层次聚类最主要的优点是集群不再需要假设为类球形。另外其也可以扩展到大数据集。
缺点:有点像 K 均值聚类,该算法需要设定集群的数量(即在算法完成后需要保留的层次)。
Python 实现:http://scikit-learn.org/stable/modules/clustering.html#hierarchical-clustering
转载请注明出处。
 相关文章
相关文章 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
