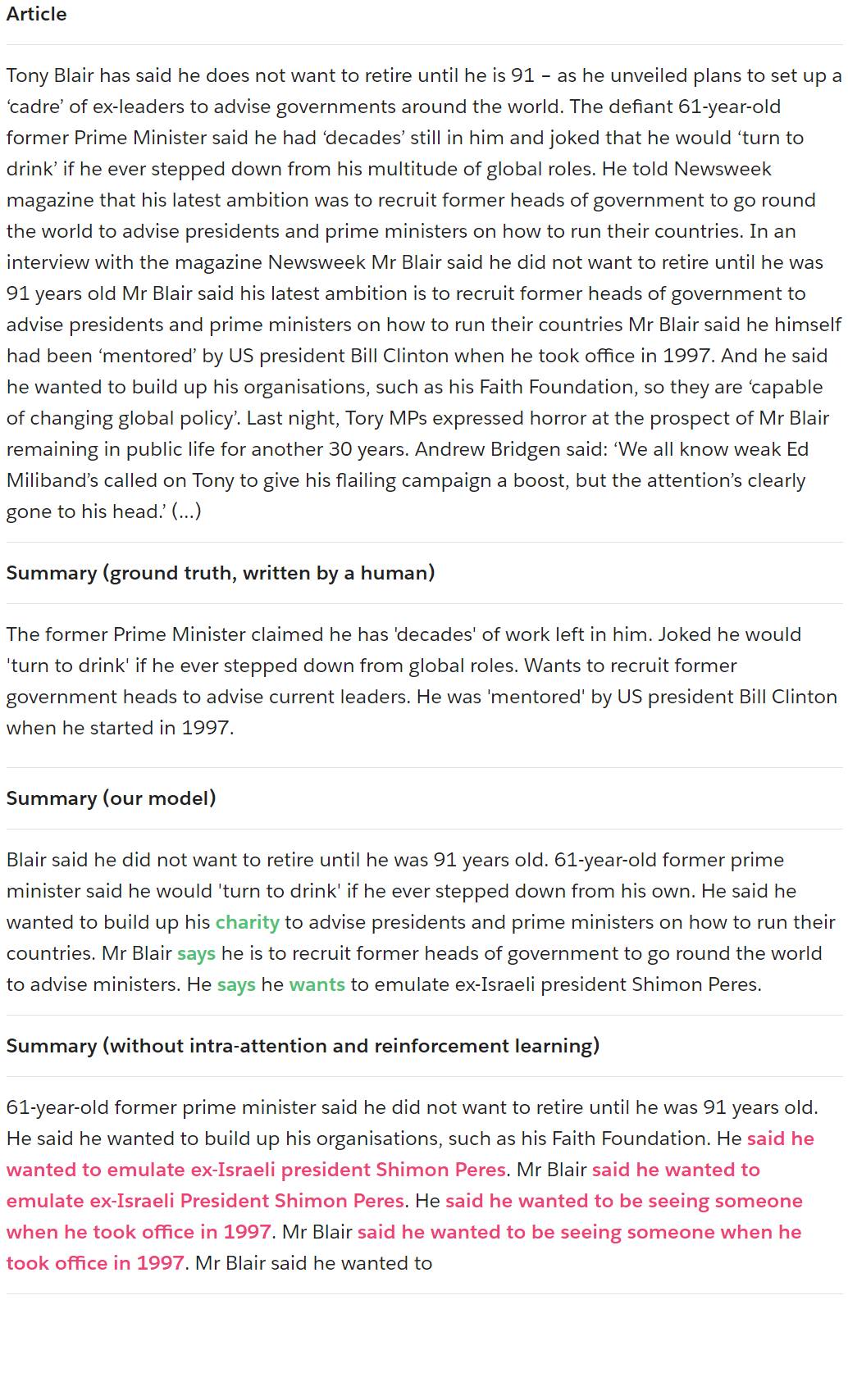
图 11:我们的模型生成的示例摘要,有和没有我们的主要贡献。原始文章中不存在的新词将以绿色显示。摘要中重复的短语显示为红色。
结论
我们的模型显著提高了在多语句摘要生成方面的最新技术水平,优于现有的抽象式模型和提取式基线。我们相信,我们的贡献(解码器内部注意模块和组合的训练目标)可以改善其他的序列生成任务,特别是较长的输出。
我们的工作也涉及诸如 ROUGE 等自动评估指标的限制,这表明需要更好的指标来评估和优化摘要模型。一个理想的度量指标在摘要的连贯性和可读性方面应与人类的判断相一致。当我们使用这样的指标来强化摘要模型时,摘要的质量可能会进一步提高。
以下为相关论文的摘要介绍:
论文:A Deep Reinforced Model for Abstractive Summarization

用于抽象式摘要的基于注意 RNN 的编码器-解码器模型已经在短输入和输出序列上取得了良好的表现。但是,对于更长的文档和摘要,这些模型通常会包含重复的和不连贯的短语。我们引入了一种带有内部注意(intra-attention)的神经网络模型和一种新的训练方法。这种方法将标准的监督式词预测和强化学习(RL)结合到了一起。仅使用前者训练的模型常常会表现出「exposure bias」――它假设在训练的每一步都会提供 ground truth。但是,当标准词预测与强化学习的全局序列预测训练结合起来时,结果得到的摘要的可读性更高。我们在 CNN/Daily Mail 和 New York Times 数据集上对这个模型进行了评估。我们的模型在 CNN/Daily Mail 数据集上得到了 41.16 的 ROUGE-1 分数,比之前的最佳模型高出了显著的 5.7 分。其也是第一个在 New York Times 语料库上表现良好的抽象式模型。人类评估也表明我们的模型能得到更高质量的摘要。
转载请注明出处。
 相关文章
相关文章 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
