现在想象一下,一个鱼缸被 256×256 个板子分割为 256×256 个部分(这个数字似乎不对),每个部分都有不同浓度的盐水。如果你去掉所有的挡板,浓度类似的小块间将不会有多少扩散,但浓度差异大的区块间有巨大的扩散。这些小块就是像素点,而浓度就是像素的亮度。浓度的扩散就是像素亮度的扩散。
这说明,扩散现象与卷积有相似点――初始状态下不同浓度的液体,或不同强度的像素。为了完成下一步的解释,我们还需要理解传播子。
理解传播子
传播子就是密度函数,表示流体微粒应该往哪个方向传播。问题是神经网络中没有这样的概率函数,只有一个卷积核――我们要如何统一这两种概念呢?
我们可以通过正规化来讲卷积核转化为概率密度函数。这有点像计算输出值的 softmax。下面就是对第一个例子中的卷积核执行的 softmax 结果:
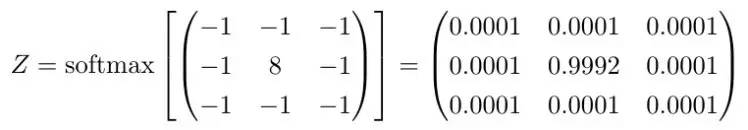
现在我们就可以从扩散的角度来理解图像上的卷积了。我们可以把卷积理解为两个扩散流程。首先,当像素亮度改变时(黑色到白色等)会发生扩散;然后某个区域的扩散满足卷积核对应的概率分布。这意味着卷积核正在处理的区域中的像素点必须按照这些概率来扩散。
在上面那个边缘检测器中,几乎所有临近边缘的信息都会聚集到边缘上(这在流体扩散中是不可能的,但这里的解释在数学上是成立的)。比如说所有低于 0.0001 的像素都非常可能流动到中间并累加起来。与周围像素区别最大的区域会成为强度的集中地,因为扩散最剧烈。反过来说,强度最集中的地方说明与周围对比最强烈,这也就是物体的边缘所在,这解释了为什么这个核是一个边缘检测器。
所以我们就得到了物理解释:卷积是信息的扩散。我们可以直接把这种解释运用到其他核上去,有时候我们需要先执行一个 softmax 正规化才能解释,但一般来讲核中的数字已经足够说明它想要干什么。比如说,你是否能推断下面这个核的的意图?
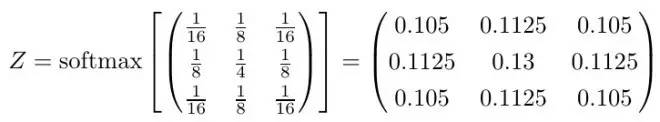
等等,有点迷惑
对一个概率化的卷积核,怎么会有确定的功能?我们必须根据核对应的概率分布也就是传播子来计算单个粒子的扩散不是吗?
是的,确实如此。但是,如果你取一小部分液体,比如一滴水,你仍然有几百万水分子。虽然单个分子的随机移动满足传播子,但大量的分子宏观上的表现是基本确定的。这是统计学上的解释,也是流体力学的解释。我们可以把传播子的概率分布解释为信息或说像素亮度的平均分布;也就是说我们的解释从流体力学的角度来讲是没问题的。话说回来,这里还有一个卷积的随机解释。
量子力学的启发
传播子是量子力学中的重要概念。在量子力学中,一个微粒可能处于一种叠加态,此时它有两个或两个以上属性使其无法确定位于观测世界中的具体位置。比如,一个微粒可能同时存在于两个不同的位置。
但是如果你测量微粒的状态――比如说现在微粒在哪里――它就只能存在于一个具体位置了。换句话说,你通过观测破坏了微粒的叠加态。传播子就描述了微粒出现位置的概率分布。比如说在测量后一个微粒可能――根据传播子的概率函数――30% 在 A,70% 在 B。
通过量子纠缠,几个粒子就可以同时储存上百或上百万个状态――这就是量子计算机的威力。
如果我们将这种解释用于深度学习,我们可以把图片想象为位于叠加态,于是在每个 3*3 的区块中,每个像素同时出现在 9 个位置。一旦我们应用了卷积,我们就执行了一次观测,然后每个像素就坍缩到满足概率分布的单个位置上了,并且得到的单个像素是所有像素的平均值。为了使这种解释成立,必须保证卷积是随机过程。这意味着,同一个图片同一个卷积核会产生不同的结果。这种解释没有显式地把谁比作谁,但可能启发你如何把卷积用成随机过程,或如何发明量子计算机上的卷积网络算法。量子算法能够在线性时间内计算出卷积核描述的所有可能的状态组合。
概率论的启发
卷积与互相关紧密相连。互相关是一种衡量小段信息(几秒钟的音乐片段)与大段信息(整首音乐)之间相似度的一种手段(youtube 使用了类似的技术检测侵权视频)。
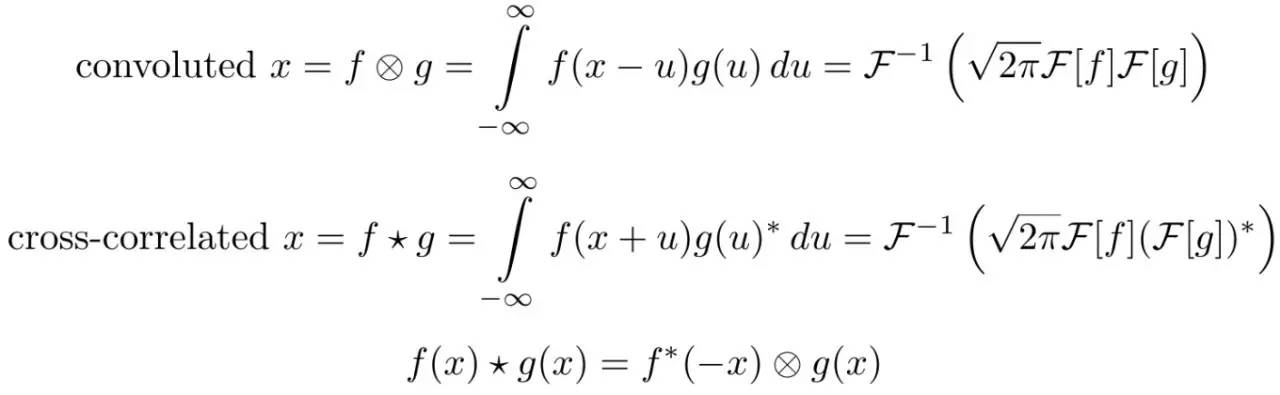
虽然互相关的公式看起来很难,但通过如下手段我们可以马上看到它与深度学习的联系。在图片搜索中,我们简单地将 query 图片上下颠倒作为核然后通过卷积进行互相关检验,结果会得到一张有一个或多个亮点的图片,亮点所在的位置就是人脸所在的位置。

这个例子也展示了通过补零来使傅里叶变换稳定的一种技巧,许多版本的傅里叶变换都使用了这种技巧。另外还有使用了其他 padding 技巧:比如平铺核,分治等等。我不会展开讲,关于傅里叶变换的文献太多了,里面的技巧特别多――特别是对图像来讲。
在更底层,卷积网络第一层不会执行互相关校验,因为第一层执行的是边缘检测。后面的层得到的都是更抽象的特征,就有可能执行互相关了。可以想象这些亮点像素会传递给检测人脸的单元(Google Brain 项目的网络结构中有一些单元专门识别人脸、猫等等;也许用的是互相关?)
统计学的启发
统计模型和机器学习模型的区别是什么?统计模型只关心很少的、可以解释的变量。它们的目的经常是回答问题:药品 A 比药品 B 好吗?
机器学习模型是专注于预测效果的:对于年龄 X 的人群,药品 A 比 B 的治愈率高 17%,对年龄 Y 则是 23%。
机器学习模型通常比统计模型更擅长预测,但它们不是那么可信。统计模型更擅长得到准确可信的结果:就算药品 A 比 B 好 17%,我们也不知道这是不是偶然,我们需要统计模型来判断。
转载请注明出处。
 相关文章
相关文章


 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
