上图:进化策略优化过程,这个环境中只有两个参数和一个奖励函数(红色=高、蓝色=低)。在每次迭代,我们都会展示当前参数值(白色)、一群经过抖动的样本(黑色)和估计的梯度(白色箭头)。我们不断将该参数移动到该箭头的顶点,直到我们收敛到了一个局部最优值。你可以使用本文的代码重现这些图。
代码示例。为了得到具体的核心算法并突出其简洁性,这里给出了一段使用进化策略优化二次函数的短代码实例(更长的版本见文末链接)。
# simple example: minimize a quadratic around some solution pointimport numpy as np solution = np.array([0.5, 0.1, -0.3]) def f(w): return -np.sum((w - solution)**2)npop = 50 # population size sigma = 0.1 # noise standard deviation alpha = 0.001 # learning rate w = np.random.randn(3) # initial guess for i in range(300): N = np.random.randn(npop, 3) R = np.zeros(npop) for j in range(npop): w_try = w + sigma*N[j] R[j] = f(w_try) A = (R - np.mean(R)) / np.std(R) w = w + alpha/(npop*sigma) * np.dot(N.T, A)
向参数中注入噪声。注意这里的目标与强化学习优化的目标是一样的:预期的奖励。但是,强化学习是将噪声注入动作空间并使用反向传播来计算参数更新,而进化策略则是直接向参数空间注入噪声。换个说话,强化学习是在「猜测然后检验」动作,而进化策略则是在「猜测然后检验」参数。因为我们是在向参数注入噪声,所以就有可能使用确定性的策略(而且我们在实验中也确实是这么做的)。也有可能同时将噪声注入到动作和参数中,这样就有可能实现两种方法的结合。
进化策略和强化学习间的权衡
相比于强化学习算法,进化策略有多个优势(一些优势有些技术性):
不需要反向传播。进化策略只需要策略的前向通过,不需要反向传播(或价值函数评估),这使得代码更短、在实践中速度快了 2-3 倍。在内存有限的系统中,也不需要保留 episode 的记录从而进行后续的更新。我们也不需要担心 RNN 中的梯度爆炸问题。最后,我们能够探索更大类别的策略函数,包括不可微分的网络(比如二值网络),或者包括复杂模块的网络(例如包括 pathfinding 或多种优化层)。
高度可并行。进化策略只需要工作器彼此之间进行少量纯数量的通信,然而在强化学习中需要同步整个参数向量(可能会是百万数值的)。直观来看,这是因为我们在每个工作器(worker)上控制随机 seeds,所以每个工作器能够本地重建其他工作器的微扰(perturbations)。结果是,在实验中我们观察到,随着我们以千为单位增加 CPU 进行优化时,有线性的加速。
高度稳健。在强化学习实现中难以设置的数个超参数在进化策略中被回避掉了。例如,强化学习不是「无标度(scale-free)的」,所以在 Atari 游戏中设置不同的跳帧(frame-skip)超参数会得到非常不同的学习输出。就像我们所展现的,进化策略在任何跳帧上有同样的结果。
架构探索。一些强化学习算法(特别是策略梯度)用随机策略进行初始化,这总是表现为在一个位置有长时间的随机跳跃。这种影响在 Q 学习方法中因为 epsilon-greedy 策略而有所缓和,其中的 max 运算能造成代理暂时表现出一些一致的动作(例如,维持一个向左的箭头)。如果代理在原地跳动,在游戏中做一些事情是更有可能的,就像策略梯度的例子一样。类似于 Q 学习,进化策略也不会受这些问题的影响,因为我们可以使用确定性策略来实现一致的探索。通过研究进化策略和强化学习梯度评估器,我们能看到进化策略是一个有吸引力的选择,特别是在 episode 中的时间步骤量很长的时候,也就是动作会有长时间的影响。或者是在没有好的价值函数评估的时候进化策略也是好的选择。
对应地,在实践中我们也发现了应用进化策略的一些挑战。一个核心问题是为了让进化策略工作,在参数中加入噪声必然会导致不同的输出,从而获得一些梯度信号。就像我们在论文中详细说明的,我们发现使用虚拟 batchnorm 能帮助缓和这一问题,但在有效地参数化神经网络上还有进一步的工作要做,从而有不同的行为作为噪声的功能。还有一个相关的困难,我们发现在 Montezuma’s Revenge 游戏中,用随机网络很难在一级的时候得到钥匙,然而用随机动作能偶尔获得钥匙。
进化策略可媲美于强化学习
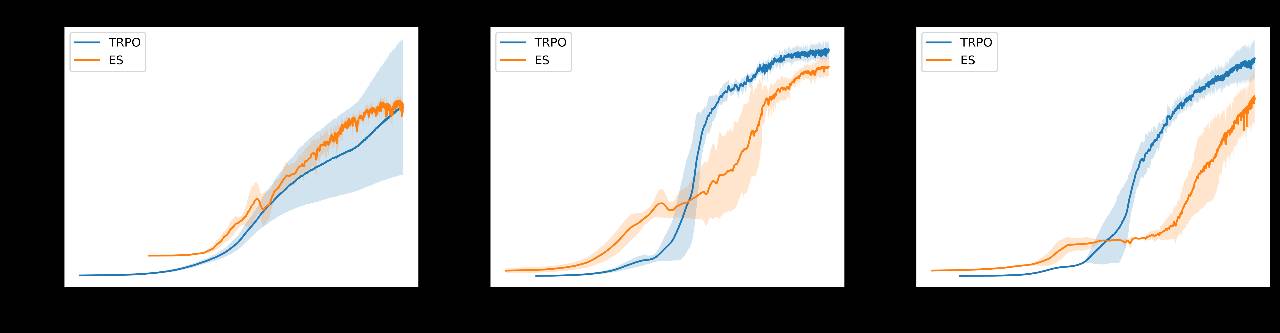
在两个强化学习基准上我们对比了进化策略和强化学习的表现:MuJoCo 控制任务和 Atari 游戏。每个 MuJoCo 任务(看以下示例)包含一个模拟身体的铰接式人物,策略网络获得所有关节的位置信息,需要输出每个关节的力矩(torques)从而前行。以下是在三个 MuJoCo 控制任务上训练的代理示例,任务目标是前行。

我们通常观察学习数据的效率来对比算法的表现。作为我们观察到的多少状态的函数,什么是我们的平均奖励?以下是我们获得的学习曲线,与强化学习进行了对比(在此案例中用的是 TRPO 强化学习算法,参考 https://arxiv.org/abs/1502.05477):
转载请注明出处。
 相关文章
相关文章 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
