至于英特尔的 Xeon Phi,广告宣称你能够使用标准 C 代码,还能将代码轻松转换成加速过的 Xeon Phi 代码。听起来很有趣,因为你可能认为可以依靠庞大的 C 代码资源。但事实上,其只支持非常一小部分 C 代码,因此,这一功能并不真正有用,大部分 C 运行起来会很慢。
我曾研究过 500 多个 Xeon Phi 集群,遭遇了无止尽的挫折。我不能运行我的单元测试(unit test),因为 Xeon Phi 的 MKL(数学核心函数库)并不兼容 NumPy;我不得不重写大部分代码,因为英特尔 Xeon Phi 编译器无法让模板做出适当约简。例如,switch 语句,我不得不改变我的 C 接口,因为英特尔 Xeon Phi 编译器不支持 C++ 11 的一些特性。这一切迫使你在没有单元测试的情况下来执行代码的重构,实在让人沮丧。这花了很长时间。真是地狱啊。
随后,执行我的代码时,一切都运行得很慢。是有 bug(?)或者仅仅是线程调度器(thread scheduler)里的问题?如果作为运行基础的向量大小连续变化,哪个问题会影响性能表现?比如,如果你有大小不同的全连接层,或者 dropout 层,Xeon Phi 会比 CPU 还慢。我在一个独立的矩阵乘法(matrix-matrix multiplication)实例中复制了这一行为,并把它发给了英特尔,但从没收到回信。所以,如果你想做深度学习,远离 Xeon Phi!
给定预算下的最快 GPU
你的第一个问题也许是:用于深度学习的快速 GPU 性能的最重要特征是什么?是 cuda 内核、时钟速度还是 RAM 的大小?
以上都不是。最重要的特征是内存带宽。
简言之,GPU 通过牺牲内存访问时间(延迟)而优化了内存带宽; 而 CPU 的设计恰恰相反。如果只占用了少量内存,例如几个数相乘(3*6*9),CPU 可以做快速计算,但是,对于像矩阵相乘(A*B*C)这样占用大量内存的操作,CPU 运行很慢。由于其内存带宽,GPU 擅长处理占用大量内存的问题。当然 GPU 和 CPU 之间还存在其他更复杂的差异。
如果你想购买一个快速 GPU,第一等重要的就是看看它的带宽。
根据内存带宽评估 GPU
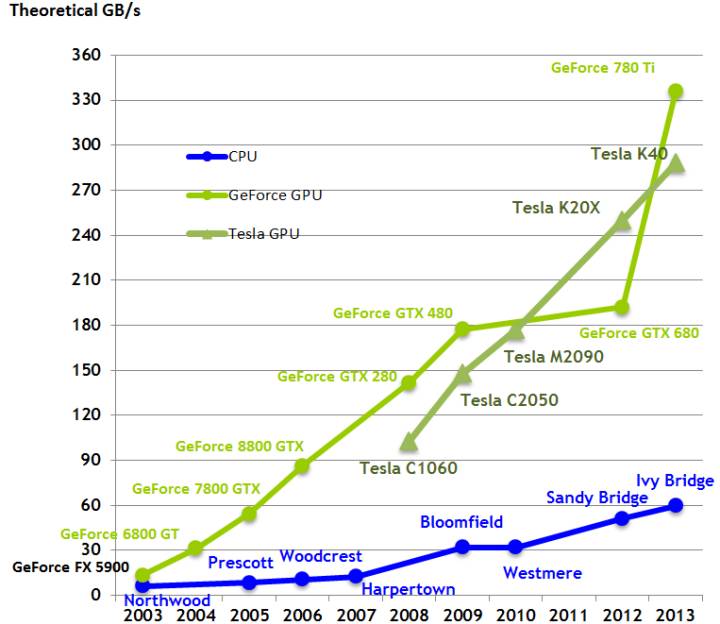
随着时间的推移,比较 CPU 以及 GPU 的带宽。为什么 GPU 计算速度会比 CPU 快?主要原因之一就是带宽。
带宽可直接在一个架构内进行比较,例如, 比较 Pascal 显卡 GTX 1080 与 GTX 1070 的性能;也可通过只查看其内存带宽而直接比较。例如,GTX 1080 (320GB/s) 大约比 GTX 1070 (256 GB/s) 快 25%。然而, 在多个架构之间,例如 Pascal 对于 Maxwell 就像 GTX 1080 对于 GTX Titan X 一样,不能进行直接比较,因为加工过程不同的架构使用了不同的给定内存带宽。这一切看起来有点狡猾,但是,只看总带宽就可对 GPU 的大致速度有一个很好的全局了解。在给定预算的情况下选择一块最快的 GPU,你可以使用这一维基百科页面(List of Nvidia graphics processing units),查看 GB/s 中的带宽;对于更新的显卡(900 和 1000 系列)来说,列表中的价格相当精确,但是,老旧的显卡相比于列举的价格会便宜很多,尤其是在 eBay 上购买这些显卡时。例如,一个普通的 GTX Titan X 在 eBay 上的价格大约是 550 美元。
然而,另一个需要考虑的重要因素是,并非所有架构都与 cuDNN 兼容。由于几乎所有的深度学习库都使用 cuDNN 做卷积运算,这就限制了对于 Kepler GPU 或更好 GPU 的选择,即 GTX 600 系列或以上版本。最主要的是 Kepler GPU 通常会很慢。因此这意味着你应该选择 900 或 1000 系列 GPU 来获得好的性能。
为了大致搞清楚深度学习任务中的显卡性能比较情况,我创建了一个简单的 GPU 等价表。如何阅读它呢?例如,GTX 980 的速度相当于 0.35 个 Titan X Pascal,或是 Titan X Pascal 的速度几乎三倍快于 GTX 980。
请注意我没有所有这些显卡,也没有在所有这些显卡上跑过深度学习基准。这些对比源于显卡规格以及计算基准(有些加密货币挖掘任务需要比肩深度学习的计算能力)的比较。因此只是粗略的比较。真实数字会有点区别,但是一般说来,误差会是最小的,显卡的排序也没问题。
也请注意,没有充分利用 GPU 的小型网络会让更大 GPU 看起来不那么帅。比如,一个 GTX 1080 Ti 上的小型 LSTM(128 个隐藏单元;batch 大小大于 64)不会比在 GTX 1070 上运行速度明显快很多。为了实现表格中的性能差异,你需要运行更大的网络,比如 带有 1024 个隐藏单元(而且 batch 大小大于 64)的 LSTM。当选择适合自己的 GPU 时,记住这一点很重要。
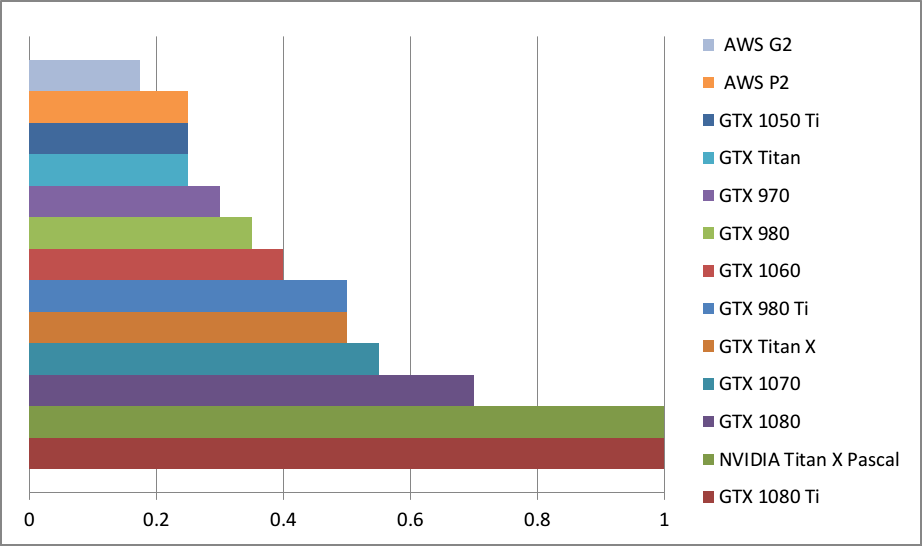
粗略的比较用于大型深度学习网络 的 GPU 性能。
总的来说,我会推荐 GTX 1080 Ti 或者 GTX 1070。它们都是优秀的显卡,如果你有钱买得起 GTX 1080 Ti 那么就入手吧。GTX 1070 更加便宜点,但是仍然比普通的 GTX Titan X (Maxwell) 要快一些。较之 GTX 980 Ti,这两者都是更佳选择,考虑到增加的 11 G 以及 8G 的内存(而不是 6G)。
8G 的内存看起来有点小,但是对于许多任务来说,绰绰有余。比如,Kaggle 比赛,很多图像数据集、深度风格以及自然语言理解任务上,你遇到的麻烦会少很多。
GTX 1060 是最好的入门 GPU,如果你是首次尝试深度学习或者有时想要使用它来参加 Kaggle 比赛。我不会推荐 GTX 1060 带有 3G 内存的变体产品,既然其他 6G 内存产品的能力已经十分有限了。不过,对于很多应用来说,6G 内存足够了。GTX 1060 要比普通版本的 Titan X 慢一些,但是,在性能和价格方面(eBay 上)都可比肩 GTX980。
如果要说物有所值呢,10 系列设计真的很赞。GTX 1060、GTX 1070 和 GTX 1080 Ti 上都很出色。GTX 1060 适合初学者,GTX 1070 是某些产业和研究部门以及创业公司的好选择,GTX 1080 Ti 通杀高端选择。
转载请注明出处。
 相关文章
相关文章 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
