阿里巴巴为什么要选择星际争霸作为AI算法研究环境?(4)
2017-05-23 编辑:
关于未来的一些思考
但是《星际争霸》里其实不光是微观战斗,其实更难的是宏观的策略方面,怎么样“宏观 + 微观”打一整个游戏,这样其实我们也有一些思考,可能不是特别成熟,但是我们可以一起探讨一下。
每一个层级设定一个 Goal
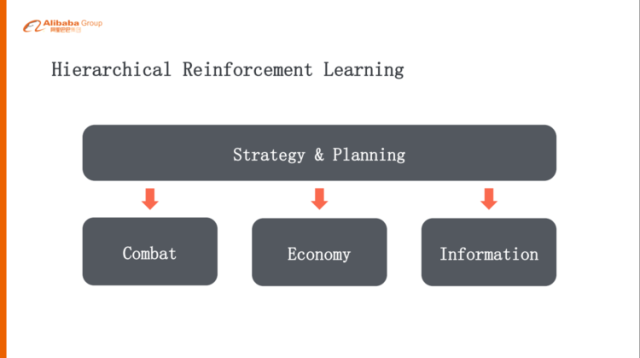
要玩一个 full-game,如果是简单的单层次的强化学习,可能解决不了问题,因为 action space 实在太大了,一个比较自然的做法就是做层级式的方式,可能上层是策略规划,下面一层就是它的战斗、经济发展、探路、地图的分析等等,这样的话一层一层的,就是高层给下层设置一个 goal,下层再给下面一层设计一个 goal,其实这跟人的问题分解是比较类似的。
模仿学习(Imitation Learning)
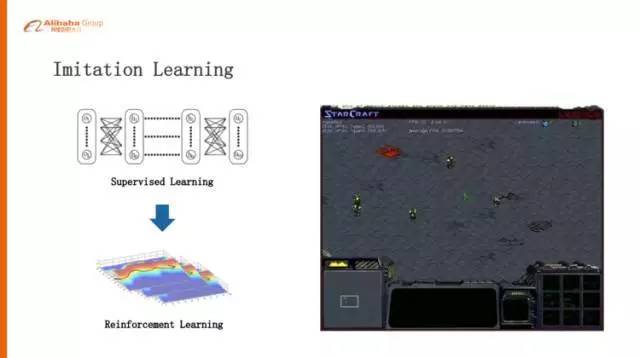
我们觉得值得去研究和探讨的是模仿学习,Imitation Learning,刚刚讲的 AlphaGo 的例子也是 Imitation Learning,第一步通过监督学习学习比较好的策略,再把监督学习学好的策略通过自我的对弈去提升,在《星际争霸》里面更需要这种模仿学习,比如说我们两个枪兵打一个小狗的时候,我们认为一个好的策略是一个枪兵吸引小狗在那儿绕圈,然后另外一个枪兵就站在中心附近开枪,把这个小狗消灭,两个枪兵一滴血可以不死。
但是这种策略是比较难学习的,所以我们先给它人为的让这个枪兵在里面画圈,画上几步之后枪兵自己学会画圈了,带着小狗,然后另外一个枪兵在后面追着屁股打,这种探索就非常的有效。
持续学习(Continual Learning)

Continual Learning,如果要迈向通用智能,这是绕不过去的课题。
Continual Learning 像人一样,我们学会了走路,下一次我们学会了说话,我们在学说话的时候可能就不会把走路这件事情这个本领忘掉,但是在《星际争霸》一些场景的时候,神经网络学到 A 的时候再去学 B,这个时候可能会把 A 的事情忘掉。
举个例子,一开始我们训练一个枪兵打一个小狗,这个小狗是电脑里边自带的 AI,比较弱,这个枪兵学会了边打边撤,肯定能把小狗打死。我们再反过来训练一个小狗,这个小狗去打电脑枪兵,这个小狗学会最佳策略就是说一直追着咬,永远不要犹豫,犹豫就会被消灭掉,所以它是一条恶狗,一直追着枪兵咬。
然后我们把这枪兵和小狗同时训练,让他们同时对弈,这样发现一个平衡态,就是枪兵一直逃,狗一直追,《星际争霸》设计比较好的就是非常平衡。然后这个枪兵就学会了一直跑,我们再把这个枪兵放回到原来的环境,就是再打一个电脑带的小狗,发现它也会一直跑,它不会边打边撤。
你发现它学习的时候,学会了 A 再学会 B,A 忘了,这个其实是对通用人工智能是非常大的挑战,最近 DeepMind 也发了一个相关工作的 paper,这也是一个 promising 的方向,大家有兴趣可以去看一下,他们的算法叫 EWC。
引入 Memory 机制
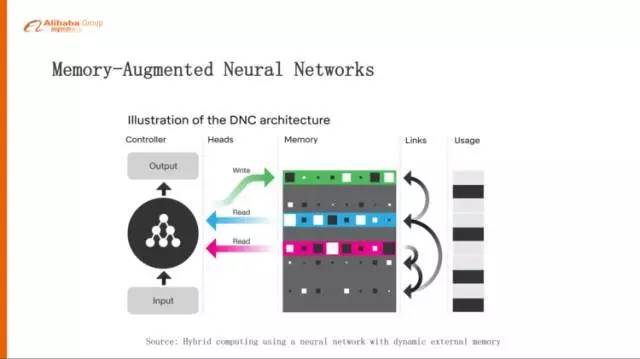
最后一点,前面有说到几大挑战,其中有一大挑战就是长期的规划,长期规划里边我们认为一个比较好的做法就是,给这种强化学习里面去引入 Memory 的机制,这也是目前的一个比较火的方向,像 Memory Networks、DNC,要解决的问题就是,我们在学习的过程当中应该记住什么东西,从而使得我们可以达到一个很好的最大的 Reward。
所以今天跟大家交流的主要就是说,其实在《星际争霸》里面是蕴含了非常非常丰富的研究通用人工智能或者研究认知智能的场景,这个里面可以有很多非常有意思的课题。我只是列举了四个方向,其实还有很多很多方向可以去研究。
欢迎有兴趣的同学跟我们一起来认真的玩游戏。谢谢大家!
作者介绍
龙海涛(花名德衡),2013 年加入阿里巴巴,现任认知计算实验室技术专家,目前主要关注深度学习、强化学习、神经科学等方面的科学和技术创新。在阿里巴巴任职期间,还负责过搜索直通车业务的架构设计,包括新一代的离线系统、在线引擎和索引内核。
今日荐文

左耳朵耗子:技术一定会让人失业,但我没有生不逢时
相关阅读:
相关推荐: