ЎѕAlphaGoГчИХКЧХЅїВЅаЎїDeepMind №юИш±ИЛ№ґ«ЖжЈєґУ16ЛкЅЈЗЕЙсНЇµЅAIі¬ј¶УўРЫ(3)
2017-05-22 ±ајЈє
ЎЎЎЎО§Же±»їґіЙКЗТ»ёцјЖЛг»ъєЬДС№ҐїЛµДУОП·Ј¬ТтОЄЛьСПЦШµШТААµУЪЦ±ѕхЎўІЯВФЛјїјЈ¬РиТЄФЪЖеЕМЙПУ®ПВ¶аіЎХЅТЫЎЈЅцЅцКЗјЗЧЎЛщУРµДЖеЧУО»ЦГЧйєПЎўЖА№АЖеѕЦЎў№№ФмєНЦґРРУ®ЖеµДІЯВФЈ¬¶ФУЪµҐМЁјЖЛг»ъАґЛµЈ¬КЗ·ЗіЈУРДС¶ИµДЎЈ
ЎЎЎЎµ«КЗХвР©¶јГ»ДЬЧиЦ№DeepMind µДAlphaGoЈ¬ЛьХЅК¤БЛХвТ»ЗРЎЈAlphaGoµДЙо¶ИЙсѕНшВзИГЛьДЬЧФјєС§»бПВЖеЎЈіМРтФ±ГЗЙиЦГБЛ№ШУЪО§ЖеµД»щґЎЖф·ўКЅЈЁheuristicsЈ©Ј¬ёшAlphaGoТ»ёцКэѕЭївЈ¬ґУ160,000ёцПЦКµЙъ»оЦРµДО§Же¶ФЮДУОП·ЦРійИЎіц3000НтёцЖеѕЦЈ¬ АґЅшРР·ЦОцЈ¬·ЦЅвЖдєЛРДЛјПлЈ¬И»єуЈ¬јЖЛг»ъДЬКэ°ЩНтґОµШЦШёґУОП·Ј¬ФЪХвТ»№эіМЦРЅшРРС§П°ЎЈ
ЎЎЎЎХвёцІЯВФТСѕУРЛщ»Ш±ЁЎЈ 2015Дк10ФВЈ¬AlphaGoТФ5Јє0 µД±И·ЦХЅК¤Е·ЦЮ№Ъѕь·®чвЈ¬ХвКЗАъК·ЙПµЪТ»ґОЈ¬µзДФФЪТ»ёцИ«ГжµД19x19ЖеЕМЙП»ч°ЬБЛТ»ГыЧЁТµИЛКїЎЈ 2016Дк3ФВЈ¬Ль»ч°ЬБЛє«№ъµДКАЅз№ЪѕьАоКАКЇЈ¬±И·ЦКЗ4±И1Ј¬¶шґУ2016ДкµЧµЅ2017ДкіхЈ¬AlphaGoЈЁО±Ч°іЙЎ°MagisterЎ±єНЎ°MasterЎ±Ј©ГШГЬµШґтБЛ51іЎФЪПЯ±ИИьЈ¬¶ФКЦ¶јКЗКАЅзЙПµД¶Ґј¶НжјТЎЈ
ЎЎЎЎПЦФЪЈ¬ЧоєуµД¶ФѕцјґЅ«µЅАґЈє5ФВ23ИХЈ¬AlphaGoєНКАЅзЕЕГыµЪТ»О§ЖеКЦїВЅаЅ«ФЪЦР№ъОЪХтЅшРРµЯёІ¶ФѕцЎЈ
ЎЎЎЎФЪО§ЖеЙПµДіЙѕНК№µГAlphaGoіЙОЄБЛѕЫ№вµЖµДЅ№µгЈ¬µ«КЗЈ¬DeepMind µДХвТ»іМРт»№УРБнНвТ»Р©¶«ОчЈ¬ТІѕНКЗЦЗБ¦ЈЁMindЈ©ЎЈDeepMindµДБЄєПґґКјИЛDemis Hassabis±нКѕЈєЎ°ЧЬ¶шСФЦ®Ј¬ОТГЗµД№¤ЧчЛµГчБЛАыУГЙъОпС§Жф·ў»ъЦЖЅбєПЧоПИЅшµД»ъЖчС§П°јјКхАґґґЅЁДЬ№»С§П°єНХЖОХёчЦЦМфХЅРФИООсµДґъАнИЛµДДЬБ¦ЎЈЎ±
ЎЎЎЎ¶шЗТЈ¬Из№ыІ»¶ПµШКдёшТ»ёцЅьєхНкГАµД»ъЖчИЛ¶ФКЦЈ¬Хв¶ФИЛАаАґЛµТІІўІ»КЗКІГґУРИ¤µДКВЎЈAlphaGoµД·ЫЛїЛьФЪО§ЖеЙПµДНіЦОБ¦КЗТ»ЦЦЅв·ЕЎЈИЛАаїЙТФґУЦРЅшРРС§П°ЎЈХэИз№юИш±ИЛ№ЛщЦёіцµДДЗСщЈ¬НкГА¶јПЈНыУлёьЗїµД¶ФКЦѕєИьЈ¬ХвТ»ІЕДЬМбЙэЧФјєЎЈ
ЎЎЎЎЎ°°ў¶ы·ЁµДУОП·К№ОТГЗёРµЅЅв·ЕЈ¬ТІѕНКЗЛµЈ¬Г»УРКІГґПВ·ЁКЗІ»їЙДЬµДЎ±Ј¬ЧЁТµµДО§ЖеКЦЦЬИрСтЛµЎЈ Ў°ПЦФЪГїёцИЛ¶јКФНјТФТ»ЦЦТФЗ°Г»УРіўКФ№эµД·зёсАґПВЖеЎЈЎ±
ЎЎЎЎµ«КЗЈ¬AlphaGoµДК¤АыІўІ»НкГАЎЈХэИзАоКАКЇФшѕЛµ№эµДДЗСщЈ¬Ў°»ъЖчИЛЅ«УАФ¶І»»бПсИЛАаТ»СщМе»бµЅО§ЖеЦ®ГАЎЈЎ±
ЎЎЎЎЛыїЙДЬКЗХэИ·ЎЈЦБЙЩДїЗ°АґїґКЗЈ¬ИЛАаЛщёРЦЄµДКАЅзУл»ъЖчЛщЎ°їґЎ±µЅµДКАЅзКЗЅШИ»І»Н¬µДЎЈ
ЎЎЎЎІ»№эЈ¬µ±ОТГЗµДДї±кЦ»КЗУ®µГ±ИИь»тХЯЅвѕцОКМвЈ¬ЙПГжµДХвР©»№ЦШТЄВрЈїДГОЮИЛіµАґЛµЈ¬ТІРнУРИЛ»бПІ»¶јЭК»µДУдФГЈ¬ХвЦЦРДЗйЈ¬»ъЖчїП¶ЁМе»бІ»µЅЎЈµ«КЗЈ¬ХвКЗ·сТвО¶ЧЕ»ъЖчѕНІ»ДЬёьёЯР§µШФЛЛНіЛїНЎўјхЙЩЅ»НЁУµ¶ВЎў±ЬГвКВ№КЈ¬ПыіэВ·ЕЈ¬ЙхЦБФЪІ»РиТЄѕИ»¤іµµДЗйїцП°ѲЎИЛЦ±ЅУЛНµЅТЅФєЈї
ЎЎЎЎІўЗТЈ¬Из№ыХвјюКВИ·КµИзґЛЦШТЄµД»°Ј¬ДЗГґґуК¦АоКАКЇЛщМбµЅµДЎ°ГАЎ±Ј¬ТІИ·КµФЪAlphaGoЦеõЅБЛМеПЦЎЈ
ЎЎЎЎ·®чвѕНФш¶ФAlphaGoУлАоКАКЇ±ИИьЦРµЪ¶юЕМµДЎ°µЪ37ІЅЎ±ДоДоІ»НьЈ¬Ў°ХвІ»КЗИЛАа»бПВіцАґµДЖеЎ±Ј¬·®чвЛµЈ¬Ў°ОТґУАґГ»їґµЅ№эУРИЛЧЯіцХвСщµДЖеЈ¬М«ГАБЛЎЈЎ±
ЎЎЎЎDeepMind РыІјµДОЪХтО§ЖеИЛ»ъ¶ФХЅК±јд±нЈє
ЎЎЎЎ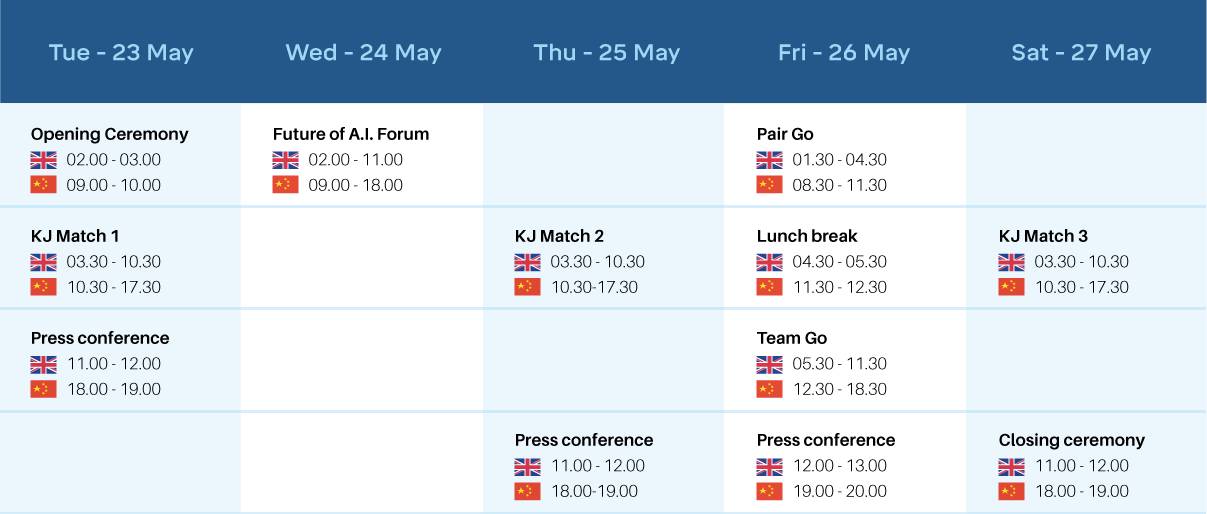
ЎЎЎЎµЪТ»МмЈ¬5ФВ23ИХЈ¬їЄД»КЅЎўїВЅаУлDeepMind±ИИьµЪТ»іЎЎўГЅМе»бЈ»
ЎЎЎЎµЪ¶юМмЈ¬5ФВ24ИХЈ¬ОґАґAIВЫМіЈ»
ЎЎЎЎµЪИэМмЈ¬5ФВ25ИХЈ¬їВЅа±ИИьµЪ¶юіЎЈ¬ГЅМе»бЈ»
ЎЎЎЎµЪЛДМмЈ¬5ФВ26ИХЈ¬ЧйєП¶ФХЅЈ¬НЕ¶У±ИИьЈ¬ГЅМе»бЈ»
ЎЎЎЎµЪОеМмЈ¬5ФВ27ИХЈ¬їВЅа±ИИьµЪИэіЎЈ¬±ХД»КЅЎЈ
Па№ШФД¶БЈє
Па№ШНЖјцЈє