技术大咖教你用TensorFlow为图片添加字幕(2)
2017-05-13 编辑:
图3中,{s0, s1, …, sN}表示我们试着去预测的字幕词汇,{wes0, wes1, …, wesN-1}是每个词的词向量。LSTM的输出{p1, p2, …, pN}是这个模型产生的句子里下一个词的概率分布。模型的训练目标是最小化对所有的词概率取对数后求和的负值。
def build_model(self):
# declaring the placeholders for our extracted image feature vectors, our caption, and our mask
# (describes how long our caption is with an array of 0/1 values of length `maxlen`
img = tf.placeholder(tf.float32, [self.batch_size, self.dim_in])
caption_placeholder = tf.placeholder(tf.int32, [self.batch_size, self.n_lstm_steps])
mask = tf.placeholder(tf.float32, [self.batch_size, self.n_lstm_steps])
# getting an initial LSTM embedding from our image_imbedding
image_embedding = tf.matmul(img, self.img_embedding) + self.img_embedding_bias
# setting initial state of our LSTM
state = self.lstm.zero_state(self.batch_size, dtype=tf.float32)
total_ loss = 0.0
with tf.variable_scope(“RNN”):
for i in range(self.n_lstm_steps):
if i > 0:
#if this isn’t the first iteration of our LSTM we need to get the word_embedding corresponding
# to the (i-1)th word in our caption
with tf.device(“/cpu:0”):
current_embedding = tf.nn.embedding_lookup(self.word_embedding, caption_placeholder[:,i-1]) + self.embedding_bias
else:
#if this is the first iteration of our LSTM we utilize the embedded image as our input
current_embedding = image_embedding
if i > 0:
# allows us to reuse the LSTM tensor variable on each iteration
tf.get_variable_scope().reuse_variables()
out, state = self.lstm(current_embedding, state)
print (out,self.word_encoding,self.word_encoding_bias)
if i > 0:
#get the one-hot representation of the next word in our caption
labels = tf.expand_dims(caption_placeholder[:, i], 1)
ix_range=tf.range(0, self.batch_size, 1)
ixs = tf.expand_dims(ix_range, 1)
concat = tf.concat([ixs, labels],1)
onehot = tf.sparse_to_dense(
concat, tf.stack([self.batch_size, self.n_words]), 1.0, 0.0)
#perform a softmax classification to generate the next word in the caption
logit = tf.matmul(out, self.word_encoding) + self.word_encoding_bias
xentropy = tf.nn.softmax_cross_entropy_with_logits(logits=logit, labels=onehot)
xentropy = xentropy * mask[:,i]
loss = tf.reduce_sum(xentropy)
total_loss += loss
total_loss = total_loss / tf.reduce_sum(mask[:,1:])
return total_loss, img, caption_placeholder, mask
使用推断来生成字幕
完成训练后,我们就获得了一个在给定图片和所有的前置词汇的前提下,可以给出字幕里下一个词概率的模型。那么我们怎么用这个模型来生成字幕?
最简单的方法就是把一张图片作为输入,循环输出下一个概率最大的词,由此生成一个字幕。
def build_generator(self, maxlen, batchsize=1):
#same setup as `build_model` function
img = tf.placeholder(tf.float32, [self.batch_size, self.dim_in])
image_embedding = tf.matmul(img, self.img_embedding) + self.img_embedding_bias
state = self.lstm.zero_state(batchsize,dtype=tf.float32)
#declare list to hold the words of our generated captions
all_words = []
print (state,image_embedding,img)
with tf.variable_scope(“RNN”):
# in the first iteration we have no previous word, so we directly pass in the image embedding
# and set the `previous_word` to the embedding of the start token ([0]) for the future iterations
output, state = self.lstm(image_embedding, state)
previous_word = tf.nn.embedding_lookup(self.word_embedding, [0]) + self.embedding_bias
for i in range(maxlen):
tf.get_variable_scope().reuse_variables()
out, state = self.lstm(previous_word, state)
# get a one-hot word encoding from the output of the LSTM
logit = tf.matmul(out, self.word_encoding) + self.word_encoding_bias
best_word = tf.argmax(logit, 1)
with tf.device(“/cpu:0”):
# get the embedding of the best_word to use as input to the next iteration of our LSTM
previous_word = tf.nn.embedding_lookup(self.word_embedding, best_word)
previous_word += self.embedding_bias
all_words.append(best_word)
return img, all_words
很多情况下,这个方法都能用。但是“贪婪”地使用下一个概率最大的词可能并不能产生总体上最合适的字幕。
规避这个问题的一个可行的方法就是“束搜索(Beam Search)”。这个算法通过递归的方法在最多长度为t的句子里寻找k个最好的候选者来生成长度为t+1的句子,且每次循环都仅仅保留最好的那k个结果。这样就可以去探索一个更大的最佳的字幕空间,同时还能让推断在可控的计算规模内。在下图的例子里,算法维护了在每个垂直时间步骤里的一系列k=2的候选句子(用粗体字表示)。
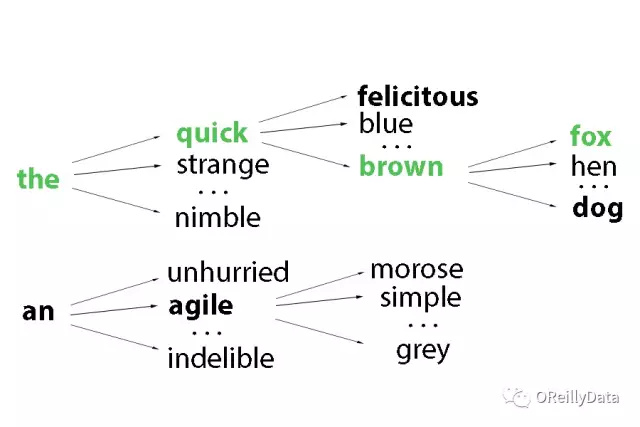
图4 来源:Daniel Ricciardelli
局限和讨论
神经图片字幕生成器给出了一个有用的框架,能学习从图片到人能理解的图片字幕间的映射。通过训练大量的图片-字幕对,这个模型学会提取从视觉特征到相关语义信息的关系。