综述 | 一文帮你发现各种出色的GAN变体(3)
2017-03-27 编辑:
他们如何强制 C 对这些特征进行编码?他们改变了损失函数以防止 GAN 简单地忽略 C。因此,他们采用一个信息理论的规则,来确保 C 与生成器分配之间的高互信息。换句话说,如果 C 改变,生成的图像也需要改变。结果,你无法明确控制哪种类型的信息会被编码进 C,但 C 的每个位置都具有唯一的含义。看一些视觉示例:

C 的第一个位置编码数字类别,而第二个位置编码旋转。
但是,不使用标签信息需要付出代价。这里的限制是这些编码仅适用于相当简单的数据集,例如 MNIST 数字。此外,你仍然需要「手工制作」C 的每个位置。例如在文章中,他们需要指定 C 的第一个位置是 0 到 9 之间的整数,因此它适用于数据集的 10 个数字类别。所以,你可能会认为这不是 100% 无监督,因为你可能需要向模型提供一些小细节。
你也许想要使用 infoGAN,如果:
你的数据集不是很复杂。
你想训练 cGAN,但你没有标签信息。
你希望看到数据集的主要的有意义的图像特征是什么,并且可以控制它们。
Wasserstein GAN
TL; DR:改变损失函数以包含 Wasserstein 距离。结果,WassGAN 具有与图像质量相关的损失函数。此外,训练稳定性也提高了,而且不依赖于架构。
[文章](https://arxiv.org/abs/1701.07875)
GAN 一直在收敛性方面存在问题,结果是,你不知道何时停止训练。换句话说,损失函数与图像质量不相关。这是一个头痛的大问题,因为:
你需要不断查看样本,以了解你的模型是否在正确训练。
你不知道何时应该停止训练(没有收敛)。
你没有一个量化数值告诉你调整参数的效果如何。
例如,看这两个能够完美生成 MNIST 样本的 DCGAN 的毫无信息量的损失函数图:

仅通过看这个图你知道什么时候停止训练吗?我也不行。
这个可解释性问题是 Wasserstein GAN 旨在解决的问题之一。怎么样?GAN 可被解释以最小化 Jensen-Shannon 发散,如果真和假的分布不重叠(通常是这种情况),则它为 0。所以,作者使用了 Wasserstein 距离,而不是最小化 JS 发散,它描述了从一个分布到另一个分布的「点」之间的距离。这大概是其主要思想,但如果你想了解更多,我强烈建议你访问这一链接()进行更深入的分析或阅读文章本身。
因此,WassGAN 具有与图像质量相关的损失函数并能够实现收敛。它也更加稳定,也就意味着它不依赖于架构。例如,即使你去掉批处理归一化或尝试奇怪的架构,它也能很好地工作。
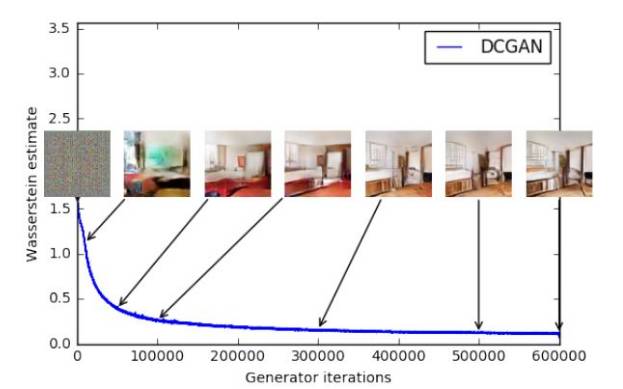
这是 WassGAN 损失函数的图。损失越低,图像质量越高。整齐!
你也许想要使用 Wasserstein GAN,如果:
你正在寻找具有最高训练稳定性的最先进的 GAN。
你想要一个有信息量的可解释的损失函数。
结语
所以,现在就是这些!我知道还有更有趣的研究去评论,但在这篇文章中,我决定专注于一个有限的集合。只是举几个例子,下面是一些我没有评论的文章的简短列表,也许你想去看看:
GAN 应用于视频:https://github.com/SKTBrain/DiscoGAN
图像完成:https://arxiv.org/abs/1609.04802
GAN + 可变性 AutoEncoder 混合:https://github.com/junyanz/iGAN
向 GAN 添加一个编码器以重建样本:https://phillipi.github.io/pix2pix/
图像到图像的翻译:https://ishmaelbelghazi.github.io/ALI/
交互式图像生成:https://arxiv.org/abs/1512.09300
使用 GAN 增加图像质量:https://bamos.github.io/2016/08/09/deep-completion/
将鞋子变成等价的包(DiscoGAN):
更广泛的研究列表,请查看此链接:https://github.com/zhangqianhui/AdversarialNetsPapers。
此外,在这个 repo(https://github.com/wiseodd/generative-models)中,你会发现 Tensorflow 和 Torch 中的各种 GAN 实现。
最后,机器之心所关注的GAN文章列表:
原文地址: