深度 | David Silver全面解读深度强化学习:从基础概念到AlphaGo
2017-03-26 编辑:
参与:马亚雄、吴攀、吴沁桐、Arac Wu
强化学习在与之相关的研究者中变得越来越流行,尤其是在 DeepMind 被 Google 收购以及 DeepMind 团队在之后的 AlphaGo 上大获成功之后。在本文中,我要回顾一下 David Silver 的演讲。David Silver 目前任职于 Google DeepMind 团队。他的演讲可以帮助我们获得对强化学习(RL)和深度强化学习(Deep RL)的基本理解,这不是一件特别难的事。
David Silver 的演讲视频可在这里查看:
在这个演讲视频中,David 做了对深度学习(DL)和强化学习(RL)的基本介绍,并讨论了如何将这两种学习方法结合成一种方法。有三种不同的可以结合深度学习和强化学习的方法:基于价值(value-based)、基于策略(policy-based)以及基于模型(model-based)的方法。在这个演讲中,David 提供了许多他们自己的实验的实例,最后以对 AlphaGo 的简单讨论结束了演讲。
概览
演讲分为五个部分:
介绍深度学习
介绍强化学习
基于价值的深度强化学习
基于策略的深度强化学习
基于模型的深度强化学习
然而,当我看完讲座、理解了各个主题之后,便决定在上述的演讲结构中引入一个新的部分——做一个深度强化学习(Deep RL)的概述。这篇文章将会按照如下组织:
介绍深度学习
介绍强化学习
深度强化学习概述
基于价值的深度强化学习
基于策略的深度强化学习
基于模型的深度强化学习
希望上述的文章结构能够帮助大家更好地理解整个主题。我会重点关注演讲视频中的重点,并尽可能去解释一些问题的复杂概念。我也会给出我自己的观点、建议以及一些可以帮助到大家的参考资料。
在深入研究更加复杂的强化学习(RL)主题之前,我会尽可能提供一些关于深度学习和强化学习的基本知识,因为对不了解这两个主题的基本知识的人而言,这个演讲是有一定难度的。希望这些基本知识可以帮助大家。如果你对自己的知识非常有信心,那么,你可以跳过文章的前两部分。
深度学习介绍
什么是深度学习?
深度学习是表征学习的通用框架,它有以下特点:
给定一个目标(objective)
学习能够实现目标的特征
直接的原始输入
使用最少的领域知识
深度学习(deep learning)的意思就是深度表征(deep representation)。
如图所示,一个深度表征由很多函数组成,它的梯度可以通过链式法则来反向传播。
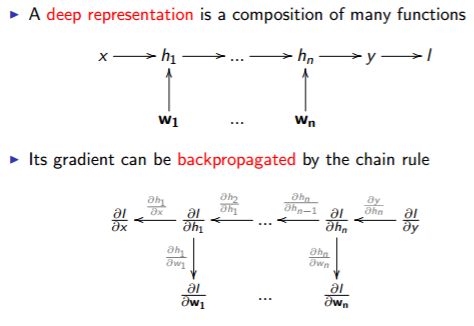
「深(deep)」的程度可以由函数或者参数的数量来推断。计算机硬件以及算法的发展使得计算机能够在合适的时间范围内完成上图所述的函数的计算,这是深度学习异军突起背后的原因。
反向传播(backpropagation)算法在解决深度问题中起着至关重要的作用。对任何一个想学习深度学习的人而言,理解反向传播是很重要的。
请不要混淆深度神经网络与深度学习。深度学习是一项实现机器学习的技术 [3]。它仅仅是一种机器学习的方法。而深度神经网络通常被人们用来理解深度表征。

深度神经网络通常包括以下内容:
线性变换、非线性激活函数、以及关于输出的损失函数,例如均方差和对数似然值。
我们用随机梯度下降的方法来训练神经网络。
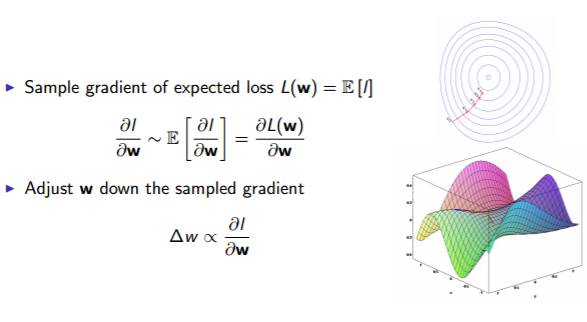
如上图所示,按照能够使得损失函数 L(W) 减小的方向去调整参数 W.
实践中一个常用的有效方法就是权值共享(Weight Sharing),它是减少参数数量的关键。有两种神经网络能够实现权值共享,即循环神经网络(Recurrent Neural Network)和卷积神经网络(ConvolutionalNeural Network)。
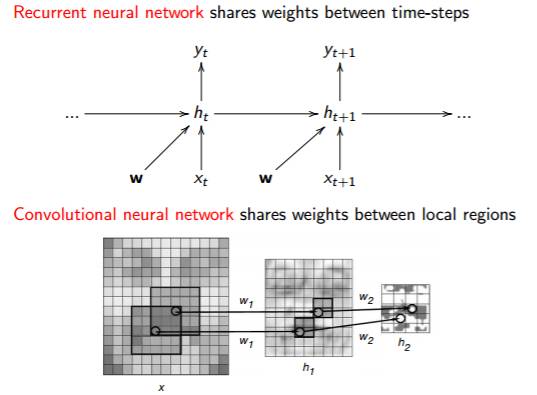
如上图所示,循环神经网络在时间步长之间共享权值,卷积神经网络在空间区域共享权值。
强化学习简介
什么是强化学习?
在这个讲座中,David给出了一张图表明强化学习在不同领域中的复杂地位,如下图所示:
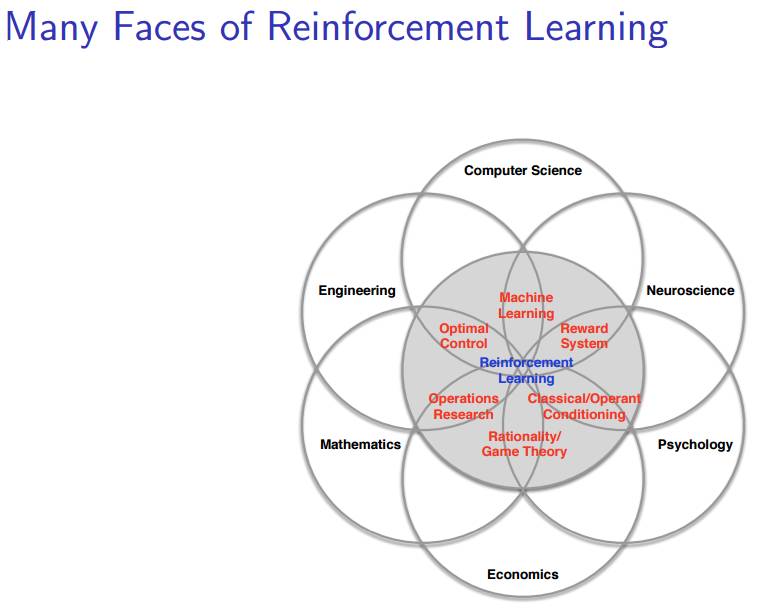
尽管我们在机器学习社区中广泛使用强化学习,但强化学习不仅仅是一个人工智能术语。它是许多领域中的一个中心思想,因此图片的标题是「强化学习的多个方面(Many Face of Reinforcement Learning)」。事实上,许多这些领域面临着与机器学习相同的问题:如何优化决策以实现最佳结果。
这就是决策科学(scienceof decision-making)。在神经科学中,人类研究人脑并发现了一种遵循著名的强化算法的奖励系统。在心理学中,人们研究的经典条件反射和操作性条件反射,也可以被认为是一个强化问题。类似的,在经济学中我们研究理性博弈论;在数学中我们研究运筹学;在工程学中我们研究优化控制。所有的这些问题都可以被认为一种强化学习问题—它们研究同一个主题,即为了实现最佳结果而优化决策。
强化学习是一个由行为心理学启发的机器学习领域 [4]。举个例子,一个学生名叫 Mike,如果他今天阅读了一篇与强化学习相关的论文,他将会在昨天的分数的基础上获得 1 分的奖励(称作正反馈)。如果他打了一整天的篮球,他的分数将会被扣掉 1 分(称为负反馈)。因而,如果 Mike 想每天都想获得更多的奖励(正反馈),他会每天都去学习。